
機械学習でのモデル構築のステップについて
皆さんは機械学習を行って予想モデルを構築するときに、どのようなステップで行っていきますか?
ここでは予測モデルを構築するステップについて説明していきます。
予測モデルを構築するステップには大きく分けて次の4つのステップから成り立ちます。
- データの準備
- データの前処理
- モデル作成
- モデルの評価
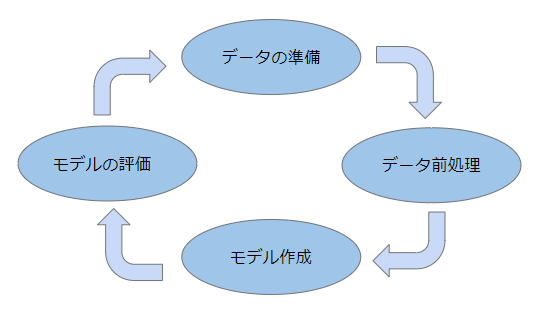
一般的に予測モデルを構築をする場合、データの準備→データの前処理→モデル作成→モデルの評価の4ステップで行っていきます。
しかし、モデルの評価を行った結果、思ったように結果が出ないということがあるかもしれません。
その場合には、何が悪かったのか分析をして、問題個所を明確にしてもう一度やり直す必要があります。
このように満足のいく結果が出るまで、このステップを何周も繰り返します。
データの準備
機械学習を行う場合、データ準備は欠かせません。大量にデータを投入することで初めて学習が有効になるからです。
特に機械学習でのデータ準備に必要なことは2つあります。それは量と質です。
量と質どちらかが欠けていても、良い精度は期待できません。
量についてはデータは少なくとも100件以上は用意しておく必要があります。100件以下の場合はサンプル数が少なくなるので精度を期待できません。
とは言ってもどうしてもデータが少ない場合もあるかと思います。
その場合は、画像データの場合はジェネレーターを利用しても良いでしょう。
ジェネレーターを使用することで、画像の回転やスケーリングを行い別の画像データとして用意できるため、画像データ数を増やすことができます。
データの質についても精査が必要です。
データ分析を行う以上は何かしらの分析する目的があるはずです。
目的の案件から考えて、どのような項目が必要かを検討する必要があります。
その目的に一切関係性が無いデータを集めたところで意味はありません。
この段階でデータの準備に不備が出てきた場合は、大きく機械学習の精度に影響してきますので非常に重要なステップとなります。
データの前処理
データを集めることができたら、次はデータの前処理です。
データの前処理とは、集めてきたデータに対して同じような基準で測定できるように変換することです。
データの前処理には以下の種類があります。
- データの欠損値の確認
- カテゴリ変数としての変換
- 特徴量の設計
- スケーリングの設計
アンケート回答をベースとしてデータについては、無回答のようにデータに欠損値が入っていることが殆どです。
また、年収の分布のデータを例とすると、一部の年収が非常に高いデータに引っ張られて、全体としてのデータがゆがんでしまう可能性があります。
このように欠損値をどうするか、外れ値をどうするかについて決定するのがデータの前処理となります。
そのほかにも、集めたデータの項目をそのまま使用するのではなく、不要な項目については削除したり、複数の項目を集めて更に別な項目として変換したりする、特徴選択や特徴変換と呼ばれる手法もあります。
ここでは詳しくは説明いたしませんので、興味がある方は調べてみてください。
モデル作成
データの前処理が終わったら次はモデルの作成です。
モデルの作成には以下の種類があります。
- ロジスティック回帰
- サポートベクターマシン(SVN)
- サポートベクターマシン(SVN) 非線形カーネル
- 多層パーセプトロン(MLP)
- k近傍法(K-NN)
- 二分探索(binary search)
- ランダムフォレスト
- CNN
- RNN
- LSTM
モデルには様々な種類があり、得意な分野や苦手な分野など特性があります。そのため分析の目的に応じたモデルを選択することが必要です。
単純な1次方程式のような単純な直線をイメージする線形回帰モデルなのか、複数の変数を使用する重回帰モデルなのか、画像の識別なのか、言語解釈なのか、というように目的に応じたモデルを選択します。
例えば、画像の識別はCNN,言語解釈の場合はRNNまたはLSTMとなります。
使用するモデルが決定したら、次はモデルに適用するパラメータを選択します。
パラメータとは誤差の範囲をどの程度まで許容するかの設定値や、どのような曲線にするかの設定値のカスタマイズのことです。
二分探索(binary search)ではどのくらいのツリーにするかを決める必要がありますが、これについてもパラメータの一つとなります。
場合によっては、パラメータを選択しなくとも内部で適切だろうと思われるパラメータを自動的に設定してくれる場合がありますが、カスタマイズすることでより適したモデルにすることが出来ます。
モデルの評価
モデルの作成が終わったら、いよいよ最後にモデルの評価を行います。
モデルの評価には以下の種類があります。
- Hold-out(ホールドアウト法)
- Cross Validation(クロスバリデーション法)
- Leave One Out
Hold-out(ホールドアウト法)とはデータ全体を学習用データとテストデータに分割し、モデルの精度を確かめる手法です。例えばデータ全体が100個ある場合、6対4の割合で分割し、学習用データを60個、テストデータを40個に分割します。
Cross Validation(クロスバリデーション法)は別名、K-分割交差検証と呼ばれます。
K-分割交差検証では、データ全体をK個に分割します。そして、そのうちの1つをテストデータとし、残る K-1 個を訓練用データに分解します。
その後、テストデータと学習用データを入れ替えて繰り返し、全てのケースがテスト事例となるよう検証を繰り返します。
Leave One OutはCross Validation(クロスバリデーション法)に似ていますが、データ全体のうち1つだけをテストデータとする方法です
また、バッチサイズやエポック数など、いくつの単位に分割して評価を実施するか、何回繰り返すかなど様々な要素があります。
今回は非常に基礎的なことについて説明しましたが、どのような複雑な学習でもデータの事前準備や前処理、モデル作成、評価についての流れは一緒なので覚えておいて下さい。