機械学習-癌の識別 (試験データの中身)
sklearnで練習用として癌の識別で用意されている569人分のデータの属性値は凹み,凹点,対称性等の10個 × 平均、標準誤差、最悪値と30個もあり、そのままprintで表示した場合はとても見えずらい形になっています。そのためpandasを利用して見やすい表に変換してみました。
癌の識別自体のプログラムについては以下の記事を確認してください
癌の識別の属性データ
属性データとしては以下の30種類が存在します。
「半径、テクスチャ、周囲、面積、滑らかさ、コンパクト、凹み、凹点、対称性、フラクタル次元」 × 「平均、標準誤差、最悪値」
printの表示
|
1 2 3 |
from sklearn.datasets import load_breast_cancer data = load_breast_cancer() print(data.feature_names) |
|
1 2 3 4 5 6 7 8 9 |
['mean radius' 'mean texture' 'mean perimeter' 'mean area' 'mean smoothness' 'mean compactness' 'mean concavity' 'mean concave points' 'mean symmetry' 'mean fractal dimension' 'radius error' 'texture error' 'perimeter error' 'area error' 'smoothness error' 'compactness error' 'concavity error' 'concave points error' 'symmetry error' 'fractal dimension error' 'worst radius' 'worst texture' 'worst perimeter' 'worst area' 'worst smoothness' 'worst compactness' 'worst concavity' 'worst concave points' 'worst symmetry' 'worst fractal dimension'] |
属性データの名称が分かります。凹み,凹点,対称性等の10個 × 平均、標準誤差、最悪値それぞれのデータが用意されています(合計 30個)
|
1 |
print(data.data) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 ..., 2.65400000e-01 4.60100000e-01 1.18900000e-01] [ 2.05700000e+01 1.77700000e+01 1.32900000e+02 ..., 1.86000000e-01 2.75000000e-01 8.90200000e-02] [ 1.96900000e+01 2.12500000e+01 1.30000000e+02 ..., 2.43000000e-01 3.61300000e-01 8.75800000e-02] ..., [ 1.66000000e+01 2.80800000e+01 1.08300000e+02 ..., 1.41800000e-01 2.21800000e-01 7.82000000e-02] [ 2.06000000e+01 2.93300000e+01 1.40100000e+02 ..., 2.65000000e-01 4.08700000e-01 1.24000000e-01] [ 7.76000000e+00 2.45400000e+01 4.79200000e+01 ..., 0.00000000e+00 2.87100000e-01 7.03900000e-02]] |
属性データの詳細データが分かります。30個の属性データが569件存在します。但しそのままでは非常に見えずらい表になっています。
pandasの変換表示①
|
1 2 3 |
import pandas as pd names=pd.DataFrame(data=data.data,columns=data.feature_names) names |
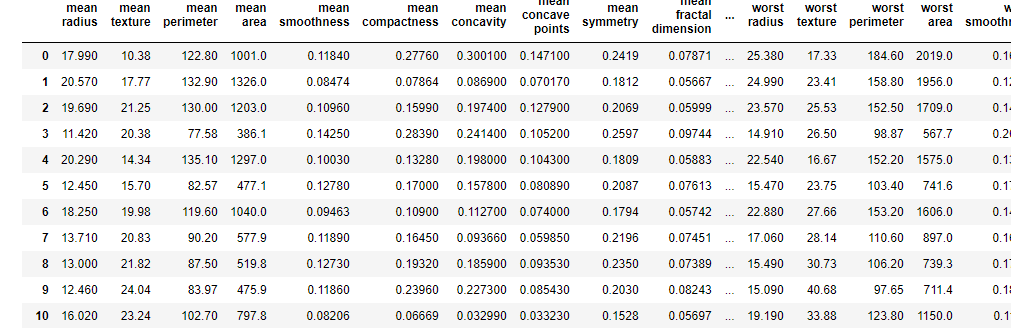
pandasのDataFrameの引数として(data=データ名、columns=カラム名)を入力することでpandasで表形式に変換してくれます。そのままprint表記するよりも視覚的に分かりやすい表になってます。右側にはみ出している箇所についてはスクロールで確認することが出来ます。
pandasの変換表示②
|
1 2 3 |
import pandas as pd names=pd.DataFrame(data=data.data,columns=data.feature_names) print(names) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mean radius mean texture mean perimeter mean area mean smoothness \ 0 17.990 10.38 122.80 1001.0 0.11840 1 20.570 17.77 132.90 1326.0 0.08474 2 19.690 21.25 130.00 1203.0 0.10960 3 11.420 20.38 77.58 386.1 0.14250 4 20.290 14.34 135.10 1297.0 0.10030 5 12.450 15.70 82.57 477.1 0.12780 6 18.250 19.98 119.60 1040.0 0.09463 7 13.710 20.83 90.20 577.9 0.11890 8 13.000 21.82 87.50 519.8 0.12730 9 12.460 24.04 83.97 475.9 0.11860 10 16.020 23.24 102.70 797.8 0.08206 |