猫の動画を対象にディープラーニングの特徴量を可視化してみる
畳み込みニューラルネットワーク(CNN)を使用すると、「猫」や「犬」などの画像認識が非常に簡単にできてしまいます。しかしながらその中身がブラックボックスとなっているため、どのように「猫」や「犬」などの種別を切り分けているか不思議に思う人が多いのではないでしょうか?そこで今回は実際の動画を使用して、AIがどのように区別しているかを可視化してみます。以前の記事ではVGG16モデルを使用して各レイヤの特徴を可視化してみました。今回はその動画版です。
この記事では「ライオン」、「ダチョウ」、「ペンギン」の3枚の写真を用意し、VGG16ネットワークのCNNでの各レイヤにおいて、どの部分に強く反応しているかヒートマップに適用させることで、人間の目にも分かるように可視化しようと試みた記事でした。

この結果として「ライオン」の場合は大部分が顔、「ダチョウ」の場合は首と足、「ペンギン」についてはお腹の部分が重要視されていました。そこで、今回は別々の写真を用いるのではなく、1つの動画をそのまま可視化させてみようかと思います。
対象の動画
変換対象の動画は次のような動画です。最近買い始めたシャム猫です。
可視化する手法として今回もGrad-CAMの手法を用いています。Grad-CAMの手法を用いることで、画像のどの部分に反応しているかが視覚的に分かるようになります。
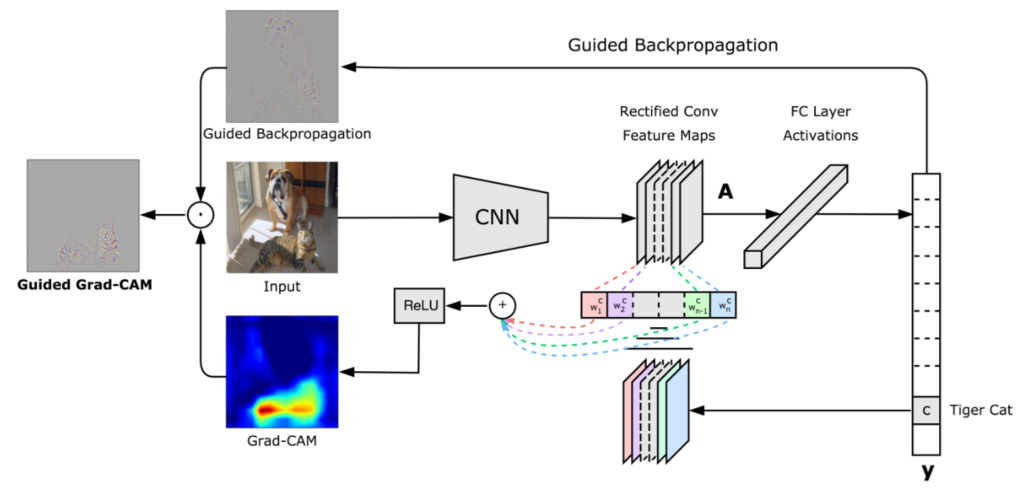
Grad-CAMの詳細は論文や他サイトで詳しく説明しているものがあるので、そちらを参照してください。
変換対象モデル
可視化対象のレイヤはVGG16モデルのblock5_conv3の部分です。VGG16モデルは名前通り16層から成り立っており最後のレイヤの畳み込み層(Conv2D)に対して可視化を行っています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 |
可視化した動画
では実際に可視化した動画です。
ファイルサイズの関係上、途中からになってしまいましたが、先ほどの動画を可視化しています。横向きの場合は鼻や口の部分について強く反応しており、前向きの場合は目より上の部分(おでこ)の部分に強く反応しているように見ます。しかし、よく見ると顔の模様に強く反応しているケースが多いです。
おそらく、VGG16のモデルでは「猫」というクラスだけではなく、「猫の種類」まで分類しているためかと思われます。しかし、一つの動画だけではなんとも言えないので、他の動画についても順次試していきたいと思います。
それにしても、ヒートマップで可視化させた動画は不思議な動画ですね。芸術分野でも何か応用が出来そうな。そんな感じがしてきます。