VGG16ネットワークの各レイヤの特徴を可視化する
今回は畳み込みニューラルネットワーク(CNN)で作られたモデルに対して各レイヤの特徴を可視化しようと思います。

畳み込みニューラルネットワーク(CNN)は画像認識などによく使われるニューラルネットワークです。画像認識といえばCNNと呼ばれるほど、多くの画像認識の技術に使われており、非常に高い成果を発揮しています。
このCNNは畳み込み層、プーリング層、全結合層などのレイヤから構成されますが、その中の畳み込み層とプーリング層を何層にもわたって積み重ねているのが特徴です。
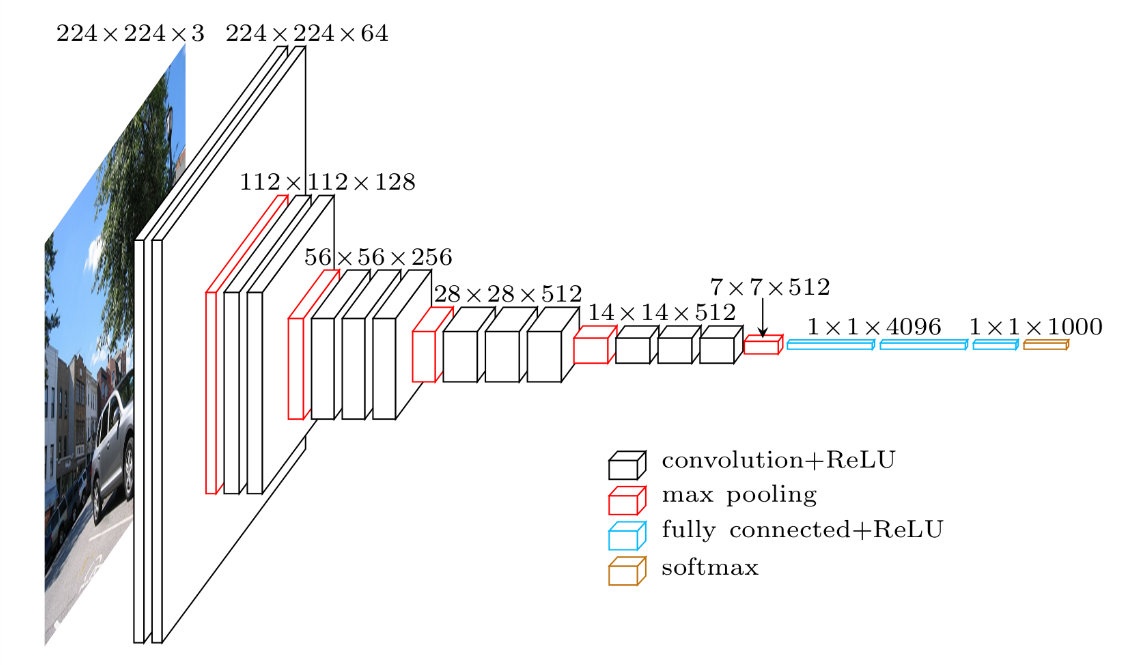
CNNは畳み込み層とプーリング層を重ね合わせることで、画像のより強い特徴を識別することができ、複雑な画像でも正しく判断できるようになります。
しかし、各レイヤの働きはブラックボックスであり、各レイヤでどのような特徴量として判断されているか分からないというケースが多いのではないでしょうか?
例えば、「犬」クラス または 「猫」クラスのどちらかを判断する画像認識があったとして、何をもって「犬」クラスと判断しているか、または何をもって「猫」クラスと判断しているのでしょうか?
そこで、各レイヤ毎の特徴マップをGrad-CAMという論文で解説されている手法で可視化しました。
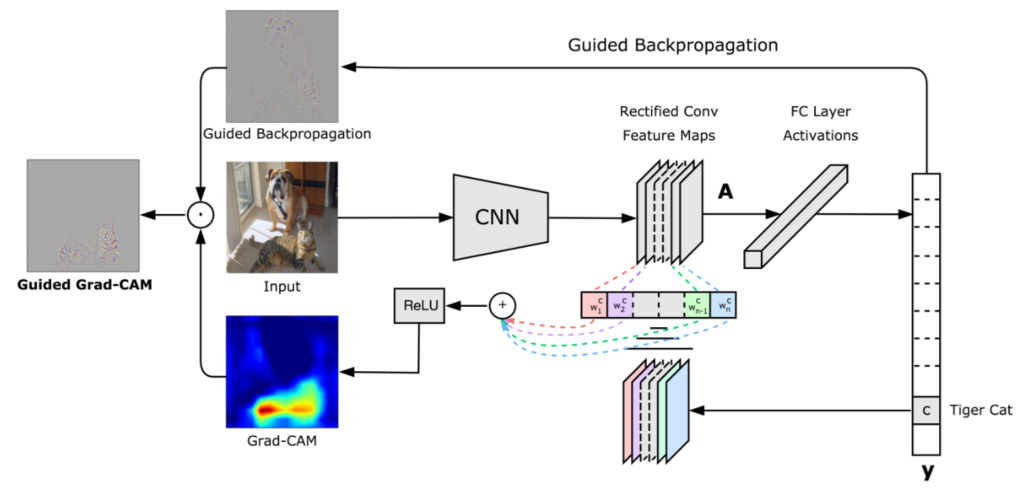
Grad-CAMの手法についてはここでは説明しませんが、簡単に言うと 「入力画像を与えることで、どこの部分が強く活性化されているか」を画像として分かるようになります。
以下のサイトが詳しく書いているので深く知りたい場合は参照してください
http://blog.brainpad.co.jp/entry/2017/07/10/163000
活性化されている箇所を画像として見ることで、何をもって「犬」クラスと判断しているか、または何をもって「猫」クラスと判断しているのか、その判断基準となる特徴箇所が分かるようになります。
今回使用するモデルとしては、VGG16を使用しています。
VGG16とは
VGG16は「ImageNet」と呼ばれる大規模画像データセットで学習されたCNNモデルです。16層から成り立っており、入力画像を1000のクラスに分類することができます.
レイヤは以下のようになっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 |
それでは早速、各層でどの部分が強く活性化されているかを確認していきましょう。
各レイヤの特徴の可視化
今回は「ペンギン」、「ダチョウ」、「ライオン」の3種類を用意しました。

これらの入力画像に対して畳み込みの以下の部分で可視化を行っていきます。
- block1_conv1~2での特徴量の可視化
- block2_conv1~2での特徴量の可視化
- block3_conv1~3での特徴量の可視化
- block4_conv1~3での特徴量の可視化
- block5_conv1~3での特徴量の可視化
block1_conv1~2での特徴量の可視化


上段の画像はヒートマップを示しており、各レイヤでの特徴量マップを示しています。下段の画像はそのヒートマップを画像に適用したものです。block1での特徴として画像のエッジをとらえており、個別の部分というよりかは全体的な特徴を示しています。
block2_conv1~2での特徴量の可視化
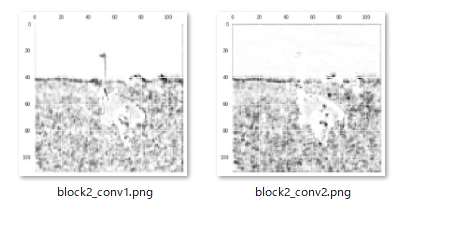

block2での特徴としてblock1同様に画像のエッジをとらえています。ただ、block1と比較してエッジに対する強度が強くなっているように見えます。
block3_conv1~3での特徴量の可視化


block3はblock1~2と異なり一部の特徴をつかみ始めてきました。ヒートマップからは全体的な画像のエッジを掴んでいるように見えますが、画像を適用した場合はその中でも一部の部分が強く反応しています。
block4_conv1~3での特徴量の可視化


block4での特徴としてblock3とほとんど同じような特徴となっていますが、強度が強くなっている特徴が少しずつ表れています。
block5_conv1~3での特徴量の可視化
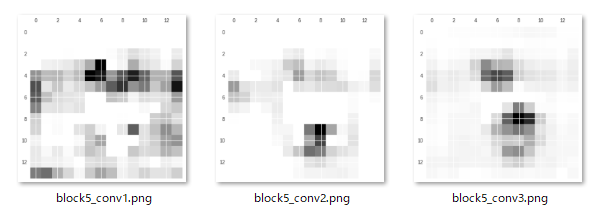

block5_conv2から特徴が一気に変わってきました。ダチョウの足と首に大きな特徴が表れ始めています。他の動物と比べるとダチョウの足と首は特徴的なものでもあるので感覚と一致します。これらの特徴を元にダチョウと判断されているようです。
block1_conv1~block5_conv3までの画像を並べると以下の通りとなります。
第1層のレイヤは全体的な特徴をとらえ、段々とレイヤを重ねるにつれて個別の特徴をとらえてきてます。

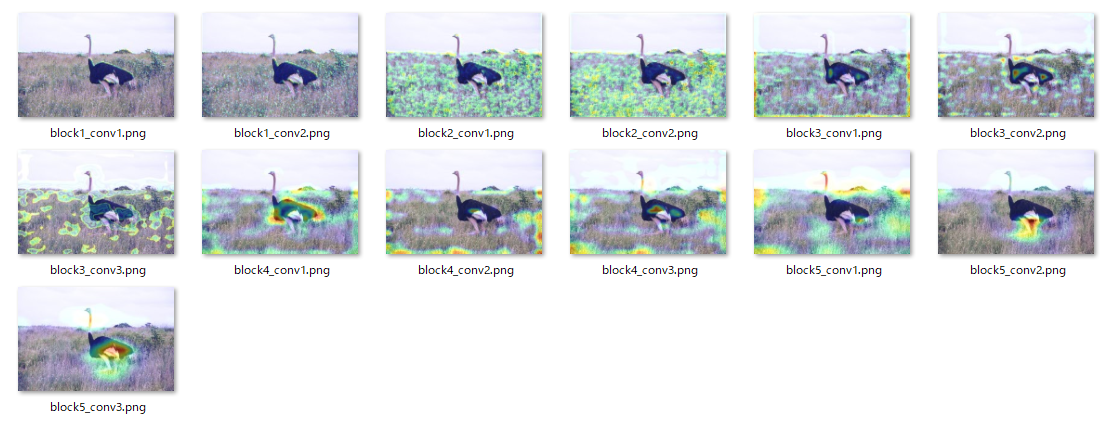
その他の「ライオン」、「ペンギン」は以下の通りです。
「ライオン」の場合


「ペンギン」の場合

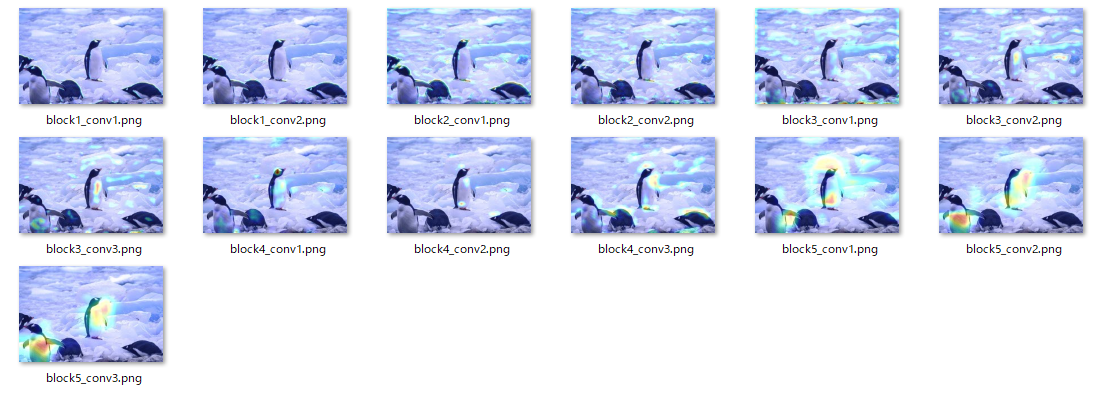
「ライオン」と「ペンギン」についても「ダチョウ」と同様に最初のレイヤは全体的な特徴をとらえ、段々とレイヤを重ねるにつれて個別の特徴をとらえてきています。
入力画像と最終層での特徴量の比較


このようにしてみると、それぞれの入力画像からどのような特徴を重要視してクラスと判断しているか分かるようになります。「ライオン」の場合は大部分が顔から判断されており、「ダチョウ」の場合は首と足が重要視されています。「ペンギン」についてはお腹の部分が重要視されています。特に「ペンギン」の場合は2匹強い反応を示していますが、その両方ともお腹の部分が協調されているのが興味深いところです。
まとめ
一般的にAIはブラックボックスと呼ばれ、どのような判断基準で正解値を求めているのか理解が出来ない場合があります。特に畳み込みニューラルネットワーク(CNN)のような層を何層か重ねたディープラーニングでは理解が顕著にしずらくなっています。そのため、画像認識ソフトを作ったものの精度が上がらないとか、どのような基準で結果を出したのか分からないという場合、手当たり次第に層を追加したり、ハイパーパラメータを変更して修正しがちです。そのような修正の場合は、何が間違っていたのか判断付きにくいため、無駄に時間を消費しがちになってしまいます。
このような時に各レイヤを可視化することで、層の深さは適切か、どのような特徴を判断しているのかが分かりやすくなります。もしかしたら顔認証を行っているつもりでも、AIとしては顔意外の背景や服装などで判断しているかもしれません。
もし、何かしら作成した画像認識の精度が予想よりも低かった場合は、次への改善につなげるために画像の可視化を取り入れることも重要かと思います。