機械学習-MNIST(概要)
TelsorFlowの公式サイトにあるMNISTについての概要を説明します。
MNISTは機械学習のHello Worldと呼ばれており、機械学習の最初のステップとなります。
MNIST For ML Beginners
https://www.tensorflow.org/versions/r1.1/get_started/mnist/beginners
Deep MNIST for Experts
https://www.tensorflow.org/versions/r1.1/get_started/mnist/pros
MNISTでの機械学習の概要
MNISTでの機械学習は0~9までの手書き文字についてその手書き文字が何の数字を表しているか予測できるように訓練していきます。
初めは60,000件の学習用のデータを用いて訓練していき、最終的に5,000件のデータを実際に判断させ、その正答率を表示します。
MNIST For ML BeginnersとDeep MNIST for Expertsでは訓練過程で使用するモデルが異なり、MNIST For ML Beginnersでは92%の正答率となり、Deep MNIST for Expertsでは99.2%程度となります。MNIST For ML Beginnersでは単なるロジスティック回帰ですが、Deep MNIST for Expertsでは「ディープラーニング」と呼ばれる多層のニューラルネットワークで生成するためです。
Deep MNIST for ExpertsではBeginnersに比べて正答率が高い一方処理時間も非常にかかります。
学習用や検証用に使用する手書き文字については次のような画像をしています。
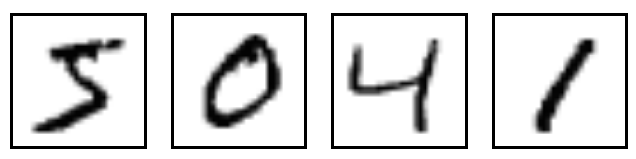
正解用のデータも別に用意されており、先ほどの例では5 0 4 1が正解となります。
MNISTでの機械学習方法は教師あり学習となっており、学習段階で画像データと正解データを伝えて訓練を繰り返していくことで数値認識の精度を向上させていきます。
使用するデータはアメリカ国立標準技術研究所提供のデータを使用しており、以下のファイルを含んでいます。
・学習用の画像データが60,000件
・学習用の正解データが60,000件
・検証用の画像データが5,000件
・検証用の正解データが5,000件
こちらの記事でも説明しています。

画像データの詳細
画像データの1文字を表すデータとしては高さ(28)×幅(28)の784byteのデータを持っています。例えば数値の"1"の場合は以下の通りとなります。
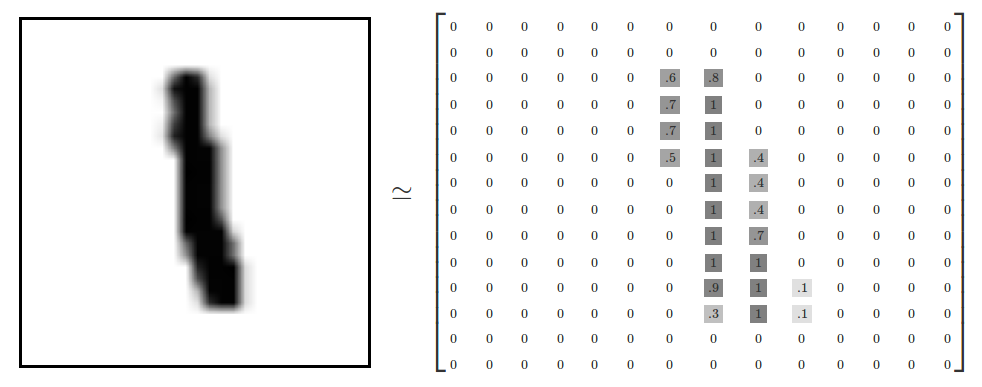
この784byteを1文字分として、学習用は60000件、検証用は5000件のデータが存在します。

縦軸は1文字分のbyte、横軸は件数です。
55,000件となっていますが例であり実際は60000件あります。
正解データの詳細
正解データとしては次のようになっています。
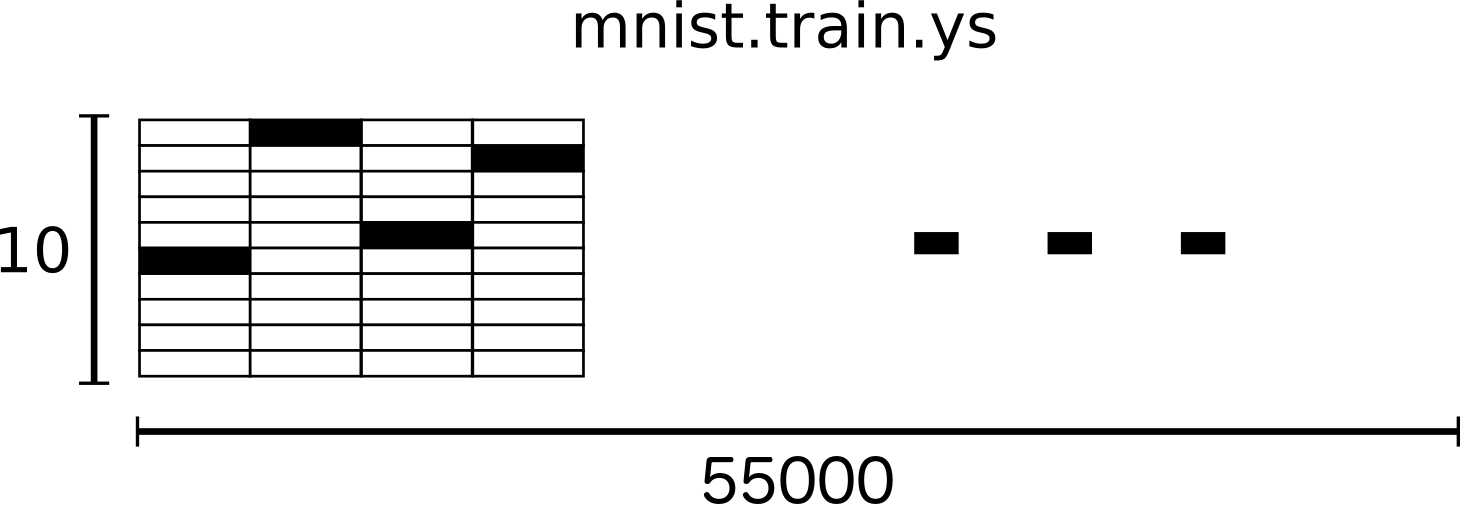
縦軸は上から0~9となり、横軸は件数です。
黒い部分は正解値となっており、例えば1文字目は5となります。
2文字目以降は 0 4 1 となっており、これらのことから1文字目~4文字目の正解値は5 0 4 1 となっていることが分かります。
55,000件となっていますが例であり実際は60000件あります。
MNIST For ML Beginnersの概要
MNIST For ML Beginnerでは学習用に使用するモデルについてソフトマックス関数(softmax)とクロスエントロピーを用いて行います。
ソフトマックス関数とクロスエントロピーの説明の前に、どのように正解値を求めていくか過程の概要を図で示します。
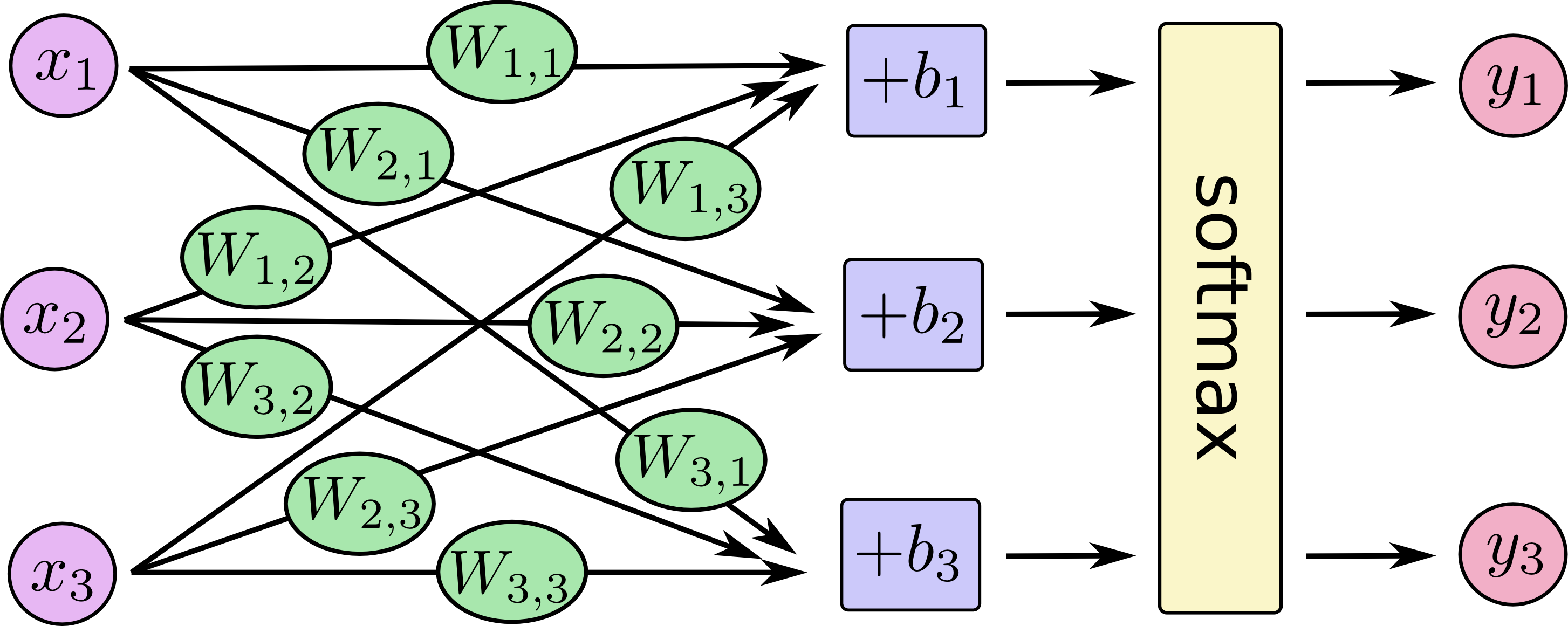
xは入力値、wは重み、bはバイアス、yが正解の確率になります。
図では簡易化されていますが実際のデータとしては以下の範囲となります。
x1~x784:入力データ (1文字を表す画像データ 高さ(28)×幅(28)の784byte)
w1~w784:重み
b1~b10:バイアス
y1~y10:正解値の確率 (0~9までに相当)
例えば"1"を表す画像データ(728byte)を入力データ(x)として与えた場合、正解の確率(y) が [y1:0.001] [y2:0.98] [y3:0.02] [y4:0.03]・・・ となることで、y2が最も高い正答率を示していると判断することが出来ます。y1,y2・・・y10は数値の0,1,2・・・9に対応しているので、1と判断されています。正解の確率は重みとバイアスを調整することで精度が上っていきます。
行列の数式で表した図が以下のようになります。
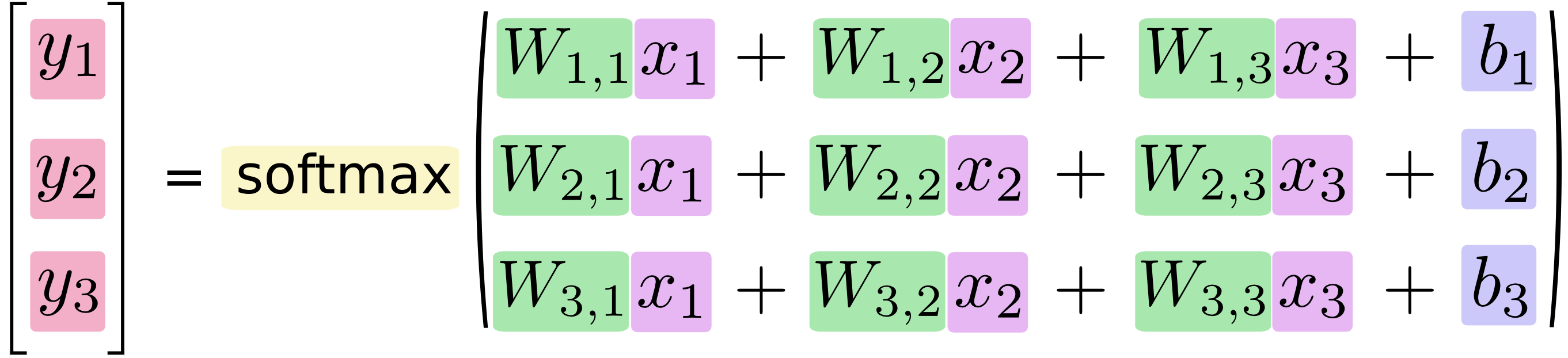
この行列の数式は次のようにも書くことが出来ます。
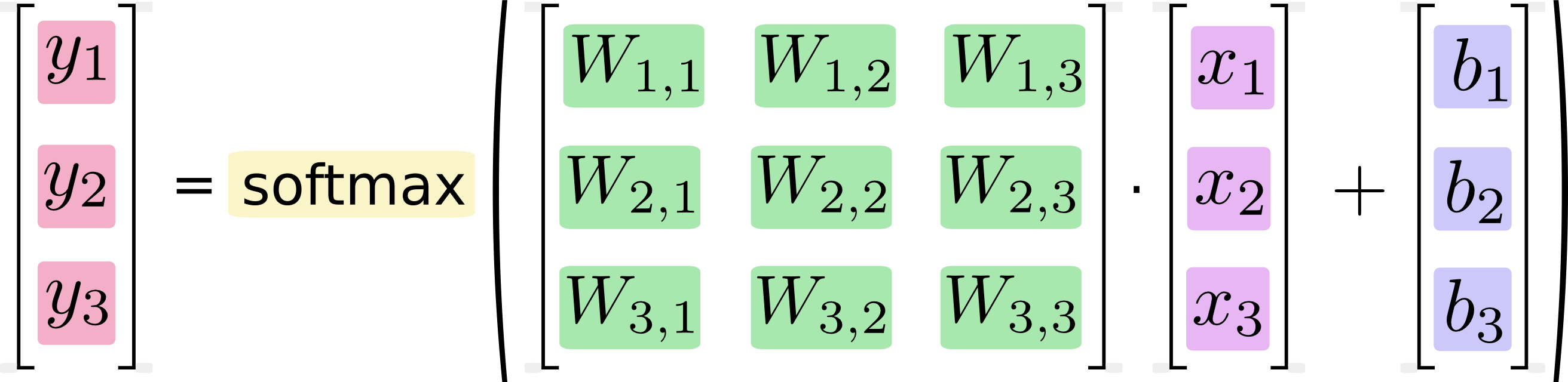
つまり、入力データ(x)に重み(w)を掛け合わせ、バイアス(b)を足したものをソフトマックス関数(softmax)に入力することで、正解値の確率(y)が出力されます。
MNIST For ML BeginnersではTelsorFlowのライブラリを用いてこの計算過程を実現します。
ソフトマックス関数について
先ほどの例では、"1"を表す画像データの正解の確率(y)は [y0:0.001] [y1:0.98] [y2:0.02] [y3:0.03]・・・としていました。この時、y0~y9までの値をすべて合計した結果は1となります。"2"を表す画像データを入力した場合でもy0~y9までの合計値は1となります。このように最終的な合計値が1となるように算出しているのがソフトマックス関数となります。
クロスエントロピーについて
教師あり学習では学習段階で画像データと正解データを伝えて訓練を繰り返していくことで画像認識の精度を向上させていきます。画像認識の精度を上げるとは重み (w)とバイアス(b)の値を正解率が高まるように調整していくことです。この調整するための値はクロスエントロピーの計算によって求められます。