機械学習-MNIST (試験データの中身)
MNIST For ML BeginnersやDeep MNIST for Expertsで機械学習を行った場合は正答率が90%以上で出力されますが、実際に学習や検証を行っているデータを直接見ることは出来ないので、何と何を比較して正答率を出したか具体的に分からない時があります。
そのため、実際に使用している画像データと比較結果(ラベル)を見てみることにします。
MNISTのデータ構成
MNISTデータは、次の4つのファイルで構成されています。
t10kで始まるデータが"検証用"、trainで始まるデータが"学習用"となっており、imagesとフェイル名につくのが画像数値データ、labelsとファイル名につくのが正解のラベルとなっています。
t10k-images-idx3-ubyte.gz:検証用の画像セット
t10k-labels-idx1-ubyte.gz:検証用のラベルセット
train-images-idx3-ubyte.gz:学習用の画像セット
train-labels-idx1-ubyte.gz:学習用のラベルセット
画像セットの解凍
画像セットはgzファイルのため圧縮されています。
win10や最新のマシンはgzファイルもデフォルトの状態で解凍できますが、解凍できない場合は解凍ソフトをダウンロードして解凍してください。
train-images-idx3-ubyte.gzを解凍すると以下のファイルが出てきます。
train-images.idx3-ubyte
バイナリソフトで中身を確認することが出来ます。

0x0000~0x0003:0x00000803
→マジックナンバー(2051)となっています。
この数値(2051)でMNISTの画像データかどうかを判断しています。
0x0004~0x0007:0x0000EA60
→画像枚数(60,000)を示しています。
0x0008~0x000b:0x0000001C
→画像の高さ(28)を示しています。
0x000c~0x000f:0x0000001C
→画像の幅(28)を示しています。
以降 28 byte(高さ)× 28 byte(幅)の画像データ(784byte)が1枚の画像データとなり、60,000枚あります。
0x0010~0x031f:1枚目の画像データ
0x0320~0x063f:2枚目の画像データ
・・・
と続きます。
画像セットのPNG画像化
次にバイナリで確認した画像セットをPNG画像化してみましょう。
フリーの数値計算ソフト GNU-Octave を使ってPNG画像に変換することが出来ます。
http://akrmys.com/public/octave/octave_install.html.ja
画像セットのPNG画像化に参考にさせていただいたサイト
https://nnet.dogrow.net/blog3/
上記サイトを元に画像セットのPNG画像化すると以下のようなファイルが作成されます。
先頭の10枚を表示させています。

これにより実際に学習用に使用した画像データがどのようなものか分かります。
ラベルセットの解凍
画像セットと同様にラベルセットもgzファイルのため圧縮されています。
win10や最新のマシンはgzファイルもデフォルトの状態で解凍できますが、解凍できない場合は解凍ソフトをダウンロードして解凍してください。
train-labels-idx1-ubyte.gzを解凍すると以下のファイルが出てきます。
train-labels-idx1-ubyte
バイナリソフトで中身を確認することが出来ます。
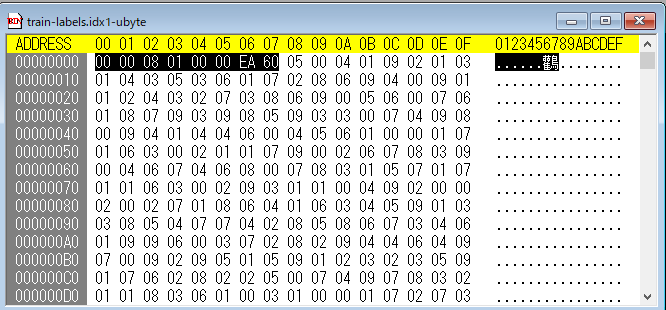
0x0000~0x0003:0x00000801
→マジックナンバー(2049)となっています。
この数値(2049)でMNISTのラベルデータかどうかを判断しています。
0x0004~0x0007:0x0000EA60
→画像枚数(60,000)を示しています。
0x0008~0xea67:各画像のラベルの値
05:1枚目のデータ
00:2枚目のデータ
04:3枚目のデータ
01:4枚目のデータ
09:5枚目のデータ
02:6枚目のデータ
01:7枚目のデータ
03:8枚目のデータ
01:9枚目のデータ
04:10枚目のデータ
・・・
と続きます。
画像セットとラベルセットの比較
先ほど表示した画像セットの先頭から10枚目の画像データは次の通りです。
ラベルセットのデータは次の通りです。
05 00 04 01 09 02 01 03 01 04
これらのことから画像セットとラベルセットの値は一致していることが分かります。
学習用の画像セットと学習用のラベルセットで確認してきましたが、検証用のデータについても同様の手順で確認することが出来ます。