Excelから読み出したデータを元に機械学習を行ってみる
機械学習を行う場合、ある一定規模のデータが必要となりますが、そのデータはExcelの形式で保存しているというケースは多いかと思います。
また、機械学習のやり方を勉強するためにサンプルソースを入力してみたものの、既に存在するExcelの形式のファイルを元に機械学習の勉強を行いたいというケースも多いかと思います。
そこで、今回はExcelから読み出したデータを元に機械学習を行ってみます。
Excelのデータとして、別記事にてskit-learn上のアヤメのデータをExcel形式に保存しているので、そのデータを使用して行っていきたいと思います。
使用するExcel
前提:
ファイル名:iris_data.xls
シート名:target
このExcelはプログラムを実行するパスと同一の直下に格納しておいてください。
データの中身は以下のようになっています。
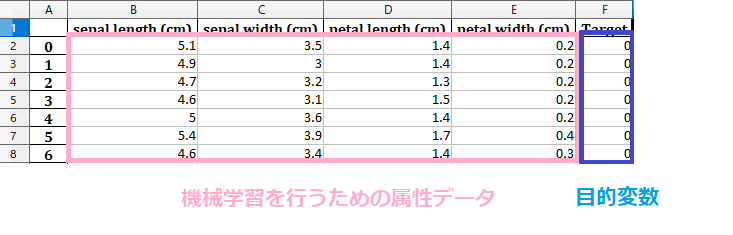
B列~E列までは属性データで、F列(Target)は目的変数とします。
ソースコード
|
1 2 3 4 5 |
from pandas import Series,DataFrame import pandas as pd # エクセルの入力ファイル名、シート名を指定 df = pd.read_excel('iris_data.xlsx',sheetname='target') |
|
1 2 |
# 読み込んだデータを表示する df.head() |
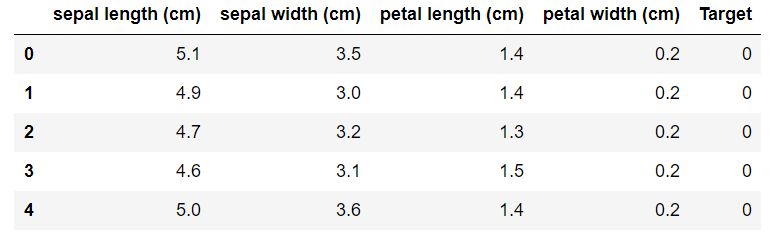
実際に読み込んだデータを表示しています。Excelのデータと同じような構造で格納されています。
|
1 2 3 |
# データをコピーする。 df_X = df.copy() df_Y = df.copy() |
属性用と目的変数用にデータを分割するため、df_X(属性用)とdf_Y(目的変数用)の2つのデータフレームにコピーします。その後不要な列を削除していきます。
|
1 2 |
#取得したExcelデータから属性データのみを取り出す df_X = df_X.drop('Target',axis=1) |
属性データにTargetの列は不要となるので、列を削除します。axis=1とは列を示しています。
|
1 2 |
# 条件のデータを表示する df_X.head() |
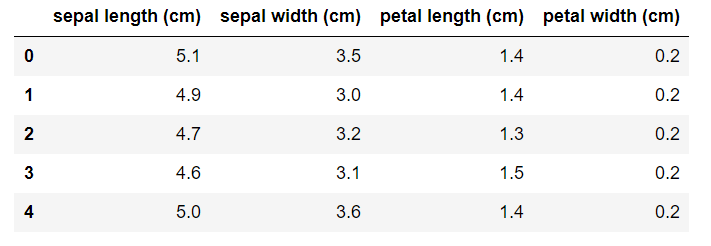
一旦表示してみましょう。期待通りのデータとなっています。
|
1 2 3 |
#取得したExcelデータから目的変数のみを取り出す drop_idx = ['sepal length (cm)', 'sepal width (cm)','petal length (cm)','petal width (cm)'] df_Y = df_Y.drop(drop_idx,axis=1) |
目的変数のみ取り出すため、その他の不要な列は削除しています。
|
1 2 |
# 条件のデータを表示する df_Y.head() |

一旦表示してみましょう。期待通りのデータとなっています。これらの手順にてExcelから読み込んだデータはPandasのデータとして格納されています。この後は通常の機械学習の手順と同一になります。
|
1 2 3 |
#訓練データと評価用データに分割 from sklearn.model_selection import train_test_split as split x_train, x_test, y_train, y_test = split(df_X,df_Y,train_size=0.8,test_size=0.2) |
訓練データと評価用データに分割します。今回は8:2で分割することにします。
|
1 2 3 4 |
#教師あり学習の実行(ロジスティック回帰) from sklearn.linear_model import LogisticRegression model= LogisticRegression() model.fit(x_train,y_train) |
|
1 2 3 4 |
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False) |
ロジスティック回帰を用いて機械学習を行っていきます。
|
1 2 3 4 5 6 7 8 |
# 評価と精度の計算 from sklearn import metrics #評価の実行 y_pred = model.predict(x_test) # 精度の計算 print(metrics.accuracy_score(y_test,y_pred)) |
|
1 |
0.933333333333 |
評価の実行です。今回の正答率は93%でした。
このようにExcelから読み出したデータについても機械学習を行うことができました。Excelを使用したデータを用いて機械学習を行う場合はほぼ同一の手順で実行することができるので、持っているExcelデータを用いていろいろ試してください。