欠損値とは何か
欠損値とはデータセットの中の空白のデータを示します。空白のデータとは何かしらの理由で、収集されていないデータのことを言います。PythonなどではNanと表示されます。
例えばアンケート調査データの場合の無回答項目やカルテデータの未検査項目等が該当します。カルテデータの未検査項目などは意図している欠損値ですが人的ミスなどによる意図しない欠損値も存在します。
意図しない欠損値とはデータの収集漏れや、システム上に不具合があってデータの変換に失敗した場合などです。また、もともとある測定項目に新しい測定項目を追加した場合も、古いデータでは測定していない項目となるため、欠損値になってしまう場合もあります。
このような欠損値のデータは除外するか、または他の値へ置き換える必要があります。
欠損値の具体例
- アンケート調査データの場合の無回答項目
- カルテデータの未検査項目
欠損値の問題点
一般的に欠損値があるデータを集計する場合、その行は削除して集計されることがほとんどです。matplotlibやseabornを使用した場合も同様で、欠損値があるデータをグラフ化した場合、欠損値があるデータは除外されてグラフ化されます。そのため気付かないうちに母数が少なくなってしまうことが起こります。
欠損値は一つも無いことが望ましいですが、そのようなデータは稀でほとんどの場合は何かしら欠損値があります。そのため、欠損値の扱いについてマスターしておく必要があります。
このページで解説する内容
- 欠損値の確認方法
- 欠損値の列/行の削除方法
- 欠損値の代入方法(平均値、中央値、最小値、最大値、固有値)
使用するサンプルデータ
Titanic: Machine Learning from Disaster
サンプルデータとして、kaggleで提供されているデータセット、Titanic: Machine Learning from Disasterを使用します。Titanic: Machine Learning from Disasterのデータはtitanic号が沈没したときの乗客員のデータです。titanic号の沈没では、多くの乗客が死亡してしまったために後から確認できない項目も多く欠損値が含まれるデータになっています。
事前準備
事前にデータセットを用意しておいてください。
訓練用ファイル:train.csv
試験用ファイル:test.csv
データセットが無い場合はkaggleのサイトからデータをダウンロードしてください。
https://www.kaggle.com/c/titanic
|
1 2 3 4 5 6 |
# 必要なモジュールをインポートします。 import numpy as np import matplotlib.pyplot as plt import seaborn as sns import pandas as pd %matplotlib inline |
|
1 2 3 |
#訓練用ファイルと試験用ファイルを読み込みます train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") |
データの先頭を表示してみましょう。
|
1 |
train_df.head() |

それぞれのカラムの意味は次のようになります。
PassengerId – 乗客識別ユニークID
Survived – 生存フラグ(0=死亡、1=生存)
Pclass – チケットクラス
Name – 乗客の名前
Sex – 性別(male=男性、female=女性)
Age – 年齢
SibSp – タイタニックに同乗している兄弟/配偶者の数
parch – タイタニックに同乗している親/子供の数
ticket – チケット番号
fare – 料金
cabin – 客室番号
Embarked – 出港地(タイタニックへ乗った港)
データの詳細を表示してみましょう。
|
1 |
train_df.describe() |
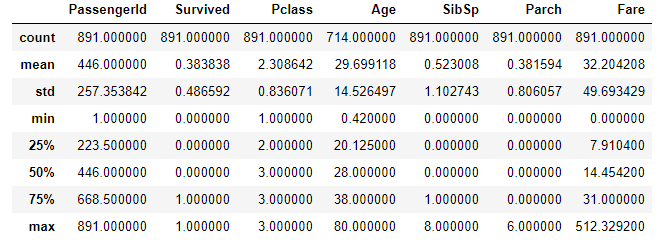
それぞれの項目の意味は次のようになります。
count–データの個数
mean–データの平均
std–データの標準偏差
min–データの最小値
25%–第一四分位数
50%–第二四分位数
75%–第三四分位数
max–データの最小値
データの要素数を表示してみましょう。
|
1 |
train_df.shape |
|
1 |
(891, 12) |
この結果により891行、12列のデータが格納されているということが分かりました。
これで一通り事前準備が完了しました。引き続き欠損値の確認を行っていきます。
欠損値の確認方法
info()を使用して総合的な情報を表示する
|
1 2 |
#infoを使用して総合的な情報を表示する train_df.info() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.6+ KB |
isnull()を使用して欠損値の有無を表示する
|
1 2 |
#isnull()を使用して欠損値の有無を表示する train_df.isnull().any(axis=0) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
PassengerId False Survived False Pclass False Name False Sex False Age True SibSp False Parch False Ticket False Fare False Cabin True Embarked True dtype: bool |
False:欠損無し
True:欠損あり
Age,Cabin,Embarkedに存在していることが一目で分かります。
isnull().sum()を使用して欠損値のカウントを表示する
|
1 2 |
#isnull().sum()を使用して欠損値のカウントを表示する train_df.isnull().sum() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64 |
pandasの表形式で欠損値のカウントを表示する
|
1 2 |
#pandasの表形式で欠損値のカウントを表示する train_df.isnull().apply(lambda col: col.value_counts(), axis=0).fillna(0).astype(np.int) |

pandasの表形式で欠損値を表示しています。先ほどと同じくAgeが177個、Cabinが687個、Embarkedが2個の欠損値となっています。
pandasの表形式で欠損値の欠損率を表示する
|
1 2 |
#pandasの表形式で欠損値の欠損率を表示する train_df.isnull().apply(lambda col: col.value_counts(), axis=0).fillna(0).astype(np.float).apply(lambda col: col/col.sum(), axis=0) |

pandasの表形式で欠損率を表示しています。
欠損値の対処法(何かしらの設定値で埋める)
続いて欠損値の対処方法について説明します。平均値、中央値、最小値、最大値、固有値で欠損値の項目を埋めていきます。今回はのAge部分について埋めて行きます。どのインデックスがのAge欠損値になっているかを見てみます。
|
1 |
train_df[train_df['Age'].isnull()].head() |

Ageの欠損値の部分について先頭5行を表示しました。インデックス5番、17番、19番、26番、28番が欠損値となっています。
平均値で埋める
|
1 2 3 4 5 |
#平均値で埋める train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") train_df["Age"].fillna(train_df.Age.mean(), inplace=True) |
|
1 |
train_df.isnull().apply(lambda col: col.value_counts(), axis=0).fillna(0).astype(np.int) |

AgeのTureが0となっており欠損値がなくなったことが分かります。実際に何の値に更新されたか確認してみましょう。
|
1 |
train_df[5:6] |
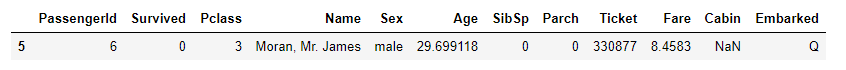
Ageの値が29.699118になっています。平均値になっていることが分かります。
中央値で埋める
|
1 2 3 4 5 |
#中央値で埋める train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") train_df["Age"].fillna(train_df.Age.median(), inplace=True) |
|
1 |
train_df.isnull().apply(lambda col: col.value_counts(), axis=0).fillna(0).astype(np.int) |
AgeのTureが0となっており欠損値がなくなったことが分かります。実際に何の値に更新されたか確認してみましょう。
|
1 |
train_df[5:6] |

Ageの値が28.0になっています。中央値になっていることが分かります。
最小値で埋める
|
1 2 3 4 5 |
#最小値で埋める train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") train_df["Age"].fillna(train_df.Age.min(), inplace=True) |
|
1 |
train_df.isnull().apply(lambda col: col.value_counts(), axis=0).fillna(0).astype(np.int) |
AgeのTureが0となっており欠損値がなくなったことが分かります。実際に何の値に更新されたか確認してみましょう。
|
1 |
train_df[5:6] |

Ageの値が0.42になっています。最小値になっていることが分かります。
最大値で埋める
|
1 2 3 4 5 |
#最大値で埋める train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") train_df["Age"].fillna(train_df.Age.max(), inplace=True) |
|
1 |
train_df.isnull().apply(lambda col: col.value_counts(), axis=0).fillna(0).astype(np.int) |
AgeのTureが0となっており欠損値がなくなったことが分かります。実際に何の値に更新されたか確認してみましょう。
|
1 |
train_df[5:6] |

Ageの値が80.0になっています。最大値になっていることが分かります。
固有値で埋める
|
1 2 3 4 5 |
#固有値で埋める train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") train_df["Age"].fillna('10', inplace=True) |
|
1 |
train_df.isnull().apply(lambda col: col.value_counts(), axis=0).fillna(0).astype(np.int) |
AgeのTureが0となっており欠損値がなくなったことが分かります。実際に何の値に更新されたか確認してみましょう。
|
1 |
train_df[5:6] |

Ageの値が10になっています。指定した設定値になっていることが分かります。
欠損値の対処法(欠損部分を削除する)
続いて欠損値の列または行の削除を行っていきます。
欠損値の列削除
|
1 2 3 4 5 |
#欠損値の列削除 train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") train_df.head() |
.png)
読み込んだばかりの列を表示します。Age,Cabin,Embarkedが存在していることを確認してください。
|
1 |
train_df.dropna(axis=1,inplace=True) |
列を削除しました。axis=1が指定されている場合は列を示しています。
|
1 |
train_df.head() |
.png)
欠損値の列を削除後を表示します。Age,Cabin,Embarkedが存在しないことを確認してください。
欠損値の行削除
|
1 2 3 4 5 |
#欠損値の行削除 train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") train_df.shape |
|
1 |
(891, 12) |
|
1 |
train_df.dropna(axis=0,inplace=True) |
|
1 |
train_df.shape |
|
1 |
(183, 12) |
まとめ
欠損値があるデータを集計する場合、その行は削除して集計されることがほとんどなので、気付かずにグラフの母数が少なくなっていたということがあります。データ集計における母数は重要となり、結果の妥当性に関わってくるもののです。しっかりと欠損値の扱いについて理解しておくようにしましょう。