
Scikit-Learnの識別器をループで一気に適用させる
今回はScikit-Learnを用いて様々な識別器を一括で適用してみます。
普通、Scikit-Learnで識別器を試す場合、一つ一つの識別器に対してfit関数で学習を行い、predict関数で予測を行い、score関数で評価を行ったりしますが、その手順が面倒だったために、ループで一括で回して評価するプログラミングを説明します。
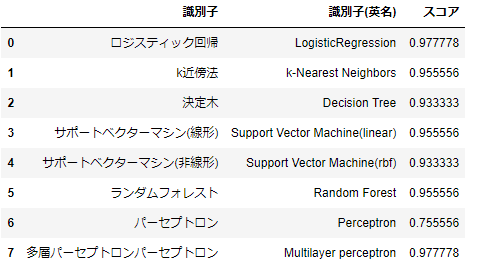
使用する識別器
以下の識別器を使用してみます
- ロジスティック回帰(LogisticRegression)
- k近傍法(k-Nearest Neighbors)
- 決定木(Decision Tree)
- サポートベクターマシン(線形)(Support Vector Machine(linear))
- サポートベクターマシン(非線形)(Support Vector Machine(rbf))
- ランダムフォレスト(Random Forest)
- パーセプトロン(Perceptron)
- 多層パーセプトロン(Multilayer perceptron)
検証データ
機械学習でよく用いられるアヤメの分類データのデータセットを使用します。
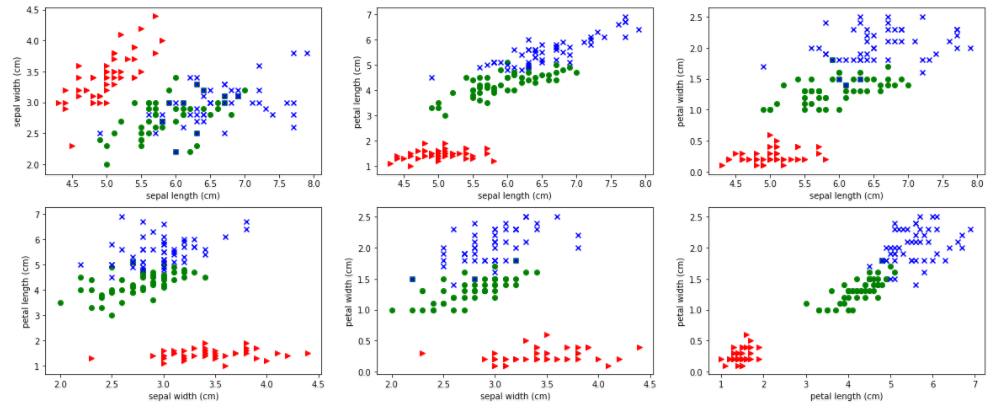
アヤメの分類とはscikit-learnライブラリに同梱されており、がく片の長さ、がく片の幅、花びらの長さ、花びらの幅の4つの説明変数からアヤメの品種を特定するデータセットです。アヤメの品種とは「setosa」、「Versicolour」、「Virginica」の3種類です。

がく片の長さ、がく片の幅、花びらの長さ、花びらの幅の4つの説明変数変数と、アヤメの品種の対応関係は次の通りです。赤、青、緑がそれぞれ「setosa」、「Versicolour」、「Virginica」のアヤメの品種に対応します。
前処理について
プログラムを簡単にするために、正規化や標準化などの前処理は一切行っていません。
150個のデータセットを7:3の割合で訓練用データと評価用データに分割しています。
では、さっそくやっていきましょう
プログラム
各種ライブラリのImport
|
1 2 3 4 5 |
#各種ライブラリのImport import pandas as pd import numpy as np import matplotlib.pyplot as plt #%matplotlib inline |
アヤメの分類のデータセットのダウンロード
|
1 2 3 |
#scikit-learnよりあやめのデータを抽出する from sklearn import datasets data = datasets.load_iris() |
説明変数と目的変数の設定
|
1 2 |
#あやめのデータ(説明変数)をdataXに格納する dataX = pd.DataFrame(data=data.data,columns=data.feature_names) |
|
1 2 3 |
#あやめのデータ(目的変数)をdataYに格納する dataY = pd.DataFrame(data=data.target) dataY = dataY.rename(columns={0: 'Species'}) |
訓練データと評価用データの分割
|
1 2 3 |
#データの分割を行う(訓練用データ 0.7 評価用データ 0.3) from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(dataX, dataY, test_size=0.3) |
これで準備が整いました。
Scikit-Learnの識別器をループで一気に適用
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import Perceptron from sklearn.neural_network import MLPClassifier #機械学習モデルをリストに格納 models = [] models.append(("ロジスティック回帰","LogisticRegression",LogisticRegression())) models.append(("k近傍法","k-Nearest Neighbors",KNeighborsClassifier())) models.append(("決定木","Decision Tree",DecisionTreeClassifier())) models.append(("サポートベクターマシン(線形)","Support Vector Machine(linear)",SVC(kernel='linear'))) models.append(("サポートベクターマシン(非線形)","Support Vector Machine(rbf)",SVC(kernel='rbf'))) models.append(("ランダムフォレスト","Random Forest",RandomForestClassifier())) models.append(("パーセプトロン","Perceptron",Perceptron())) models.append(("多層パーセプトロンパーセプトロン","Multilayer perceptron",MLPClassifier())) names_jp = [] names_en = [] results = [] for name_jp,name_en,model in models: print(model.fit(X_train,Y_train),"\n") names_jp.append(name_jp) names_en.append(name_en) results.append(model.score(X_test,Y_test)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False) KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights='uniform') DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter='best') SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False) SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False) RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False) Perceptron(alpha=0.0001, class_weight=None, eta0=1.0, fit_intercept=True, max_iter=None, n_iter=None, n_jobs=1, penalty=None, random_state=0, shuffle=True, tol=None, verbose=0, warm_start=False) MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9, beta_2=0.999, early_stopping=False, epsilon=1e-08, hidden_layer_sizes=(100,), learning_rate='constant', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True, power_t=0.5, random_state=None, shuffle=True, solver='adam', tol=0.0001, validation_fraction=0.1, verbose=False, warm_start=False) |
結果表示
|
1 2 3 4 5 6 |
list_df = pd.DataFrame( columns=['識別子','識別子(英名)','スコア'] ) for i in range(len(names_jp)): list_df = list_df.append( pd.Series( [names_jp[i],names_en[i],results[i]], index=list_df.columns ), ignore_index=True) list_df |
まとめ
データセットは用意したものの、どの識別器を使用していいのか分からない場合や、初期設定である程度高い結果を出力する識別器をとりあえず知りたいという場合はこの方法が使えます。また、今回は割愛しましたが、グリットサーチも組み合わせることで、より良い精度の高い予測するハイパーパラメータを探すことができます。