
NNC(Neural Network Console)とは
SonyのNNC(Neural Network Console)はプログラミングなしでディープランニングを実装できるツールであり、ソニーのグループ会社のソニーネットワークコミュニケーションズ社からリリースされています。
NNCはプログラミングが一切不要のGUIをベースにしたツールで、ドラッグ&ドロップによる簡単な編集で、ニューラルネットワークを設計することが出来ます。
公式サイト
Windows版とクラウド版があり、Windows版は無料で使用することができます。
Windows版
- Windows 8.1/10_64bit
クラウド版(無料利用枠)
- 実行環境:CPU
- 学習・評価実行時間:10時間
- ワークスペース:10G
- プロジェクト数:10個
無料利用枠に収まらない使用をする場合は従量制の月額料金も存在します。多少お金がかかりますが、無制限にプロジェクト数を増やしたい場合や、GPUを使用して高速演算を行いたい場合はとても便利です。
アヤメの分類とは
アヤメの分類とは機械学習によく使用される分類問題の一つです。がく片の長さや花びらの幅など、アヤメを構成する4つの属性からアヤメの種類を識別します。
機械学習やディープラーニングで非常によく使用されています。

属性
- がく片の長さ(Sepal length)
- がく片の幅(Sepal width)
- 花びらの長さ(Petal lengt
- 花びらの幅(Petal width)
識別
- setosa(ヒオウギアヤメ)
- Versicolour(ブルーフラッグ)
- Virginica
NNCでのデータセットの中身
NNC(Neural Network Console)をインストールしたディレクトリ配下の下記ディレクトリにアヤメのデータセットが入っています。
neural_network_console_110\samples\sample_dataset\iris_flower_dataset
学習用データ 120個、評価用データ 30個のフルセット
- iris_flower_dataset_all_delo.csv
- iris_flower_dataset_all_sdeepy.csv
学習用データ 120個のデータセット
- iris_flower_dataset_training_delo.csv
- iris_flower_dataset_training_sdeepy.csv
評価用データ 30個のデータセット
- iris_flower_dataset_validation_delo.csv
- iris_flower_dataset_validation_sdeepy.csv
それぞれのデータセットは学習用/評価表全てのフルセットと、学習用、または評価用のデータセットを格納した3種類に分かれています。
さらにファイル名の末尾に付与されているdeloとsdeepyの2種類の合計6つのファイルが存在します。
deloとsdeepyの違いは以下の通りです。
delo・・・アヤメの識別を0~2の数値のカテゴリとして表したもの
- Versicolour(ブルーフラッグ)(1)
- setosa(ヒオウギアヤメ)(0)
- Virginica(2)
sdeepy・・・アヤメの識別を0と1から成り立つone hot表現として表したもの
- Versicolour(ブルーフラッグ)(1,0,0)
- setosa(ヒオウギアヤメ)(0,1,0)
- Virginica(0,0,1)
今回はアヤメの識別を0~2の数値のカテゴリとして行うため、ファイルの末尾にdeloが不要されたデータを使用します。
プロジェクトファイルの作成
プロジェクトファイルを新規で作成します。
ホームボタン(家のマーク)をクリックし、画面上部中央のWindowで「New Project」を選択します。
以下の画面が立ち上がります。
CTL+S または下記のSaveボタンをクリックしてプロジェクトに名前を付けて保存します。
プロジェクト名は任意の名前で問題ありませんが、nnc_iris_flowerのような分かりやすい名前を付けておきましょう。
データセット(TRAININGデータ)の読み込み
画面上部右側のWindowで「DATASET」をクリックします。
画面左側のWindowで「Training」を選択します。
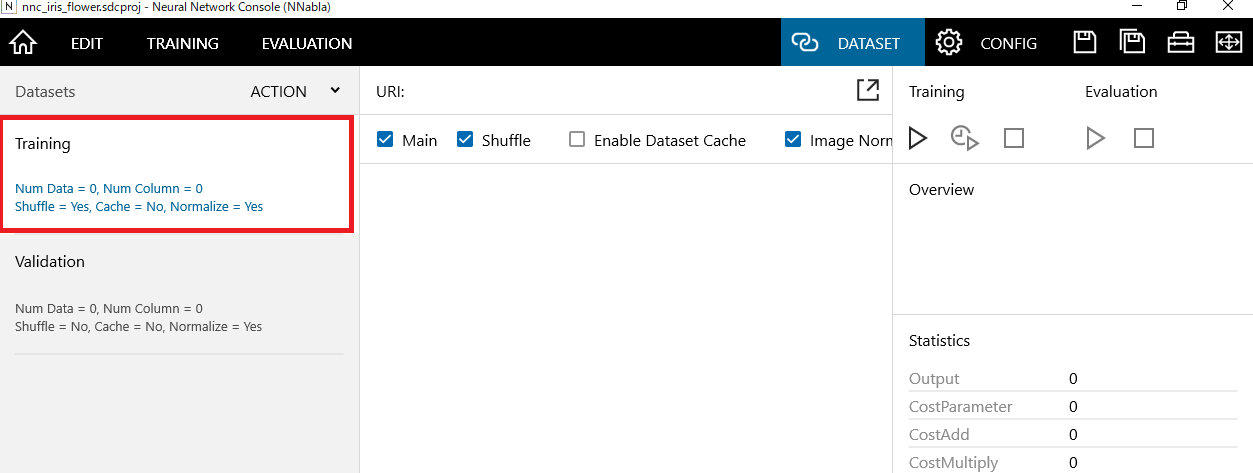
画面上部の矢印マークのアイコンをクリックし、「Open Dataset」をクリックします。
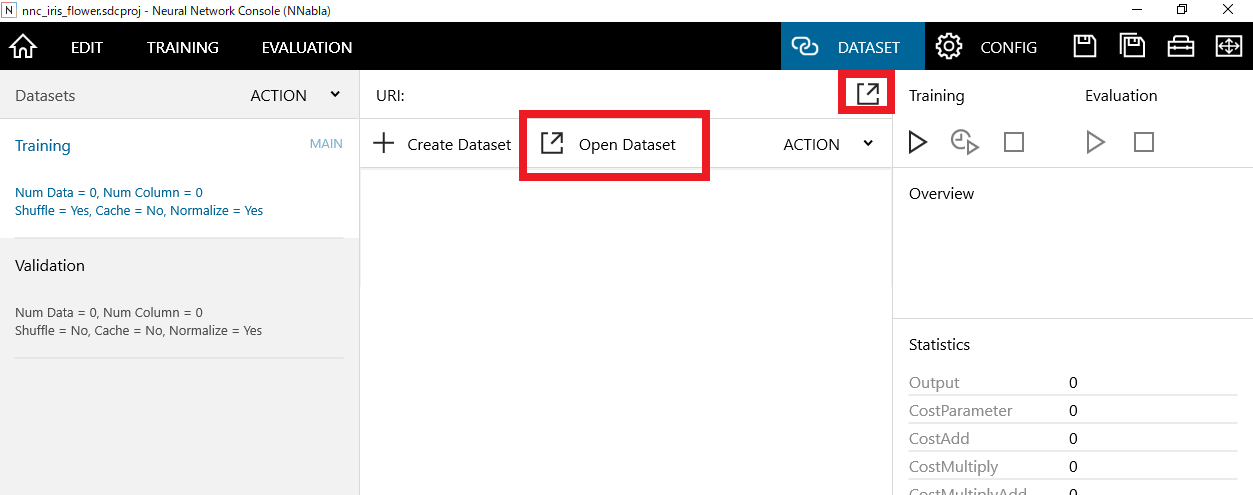
以下のファイルを選択してください。
neural_network_console_110\samples\sample_dataset\iris_flower_dataset
- iris_flower_dataset_training_delo.csv
画面左側のWindowの「Training」に
Num Data = 120
Num Column = 5
となっていることを確認してください。
データセット(EVALUATIONデータ)の読み込み
データセット(TRAININGデータ)の読み込みとほぼ同様です。
画面左側のWindowで「validation」を選択し、Training同様の操作で以下のファイルを選択してください。
neural_network_console_110\samples\sample_dataset\iris_flower_dataset
- iris_flower_dataset_validation_delo.csv
画面左側のWindowの「validation」に
Num Data = 30
Num Column = 5
となっていることを確認してください。
レイヤの作成
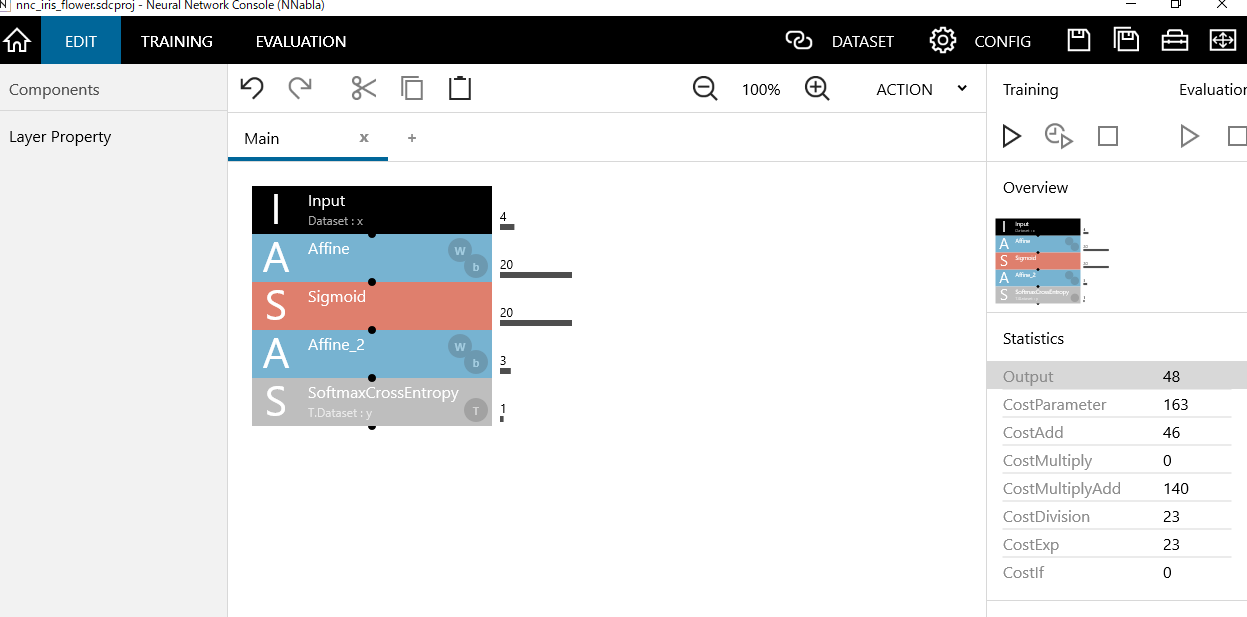
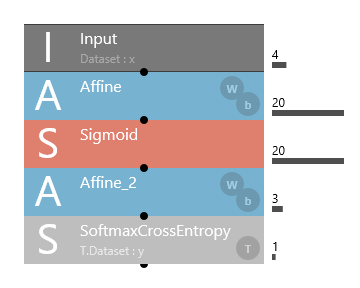
アヤメの分類を行うために以下のようなレイヤを作成します。
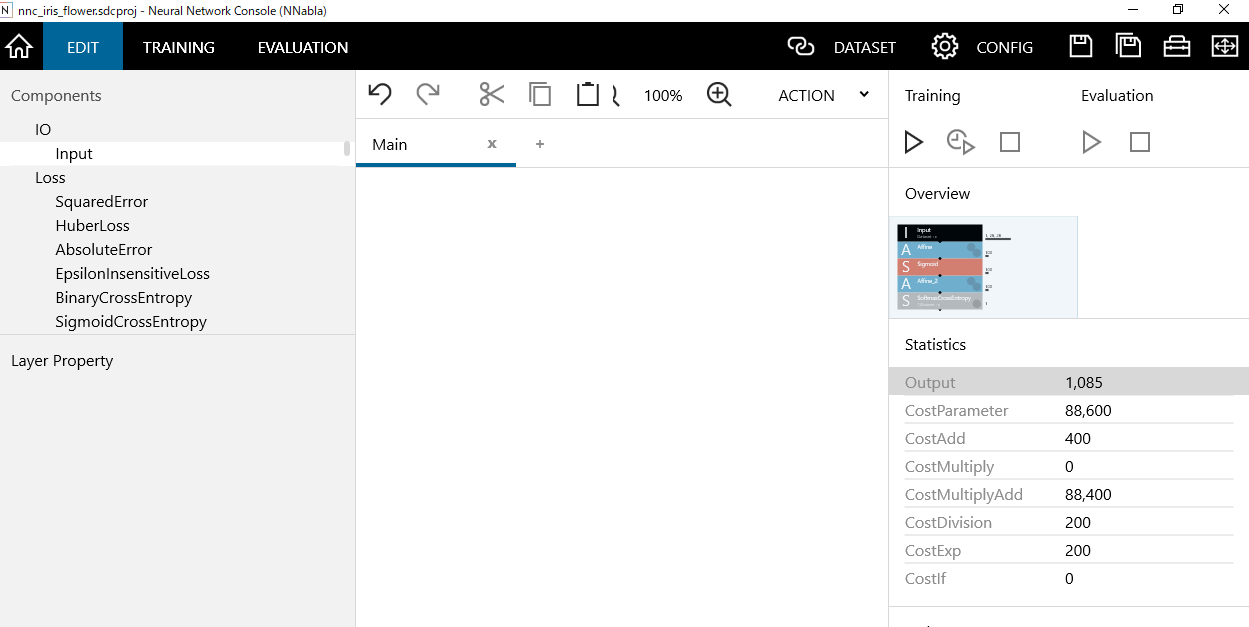
画面上部左側のWindowで「EDIT」をクリックします。
画面左側のWindowのComponentsで以下の順番でダブルクリックしてください
- IO⇒Input
- Basic⇒Affine
- Activation⇒Sigmoid
- Basic⇒Affine
- Loss⇒SoftmaxCrossEntopy
以下の画面が出力されていれば成功です。
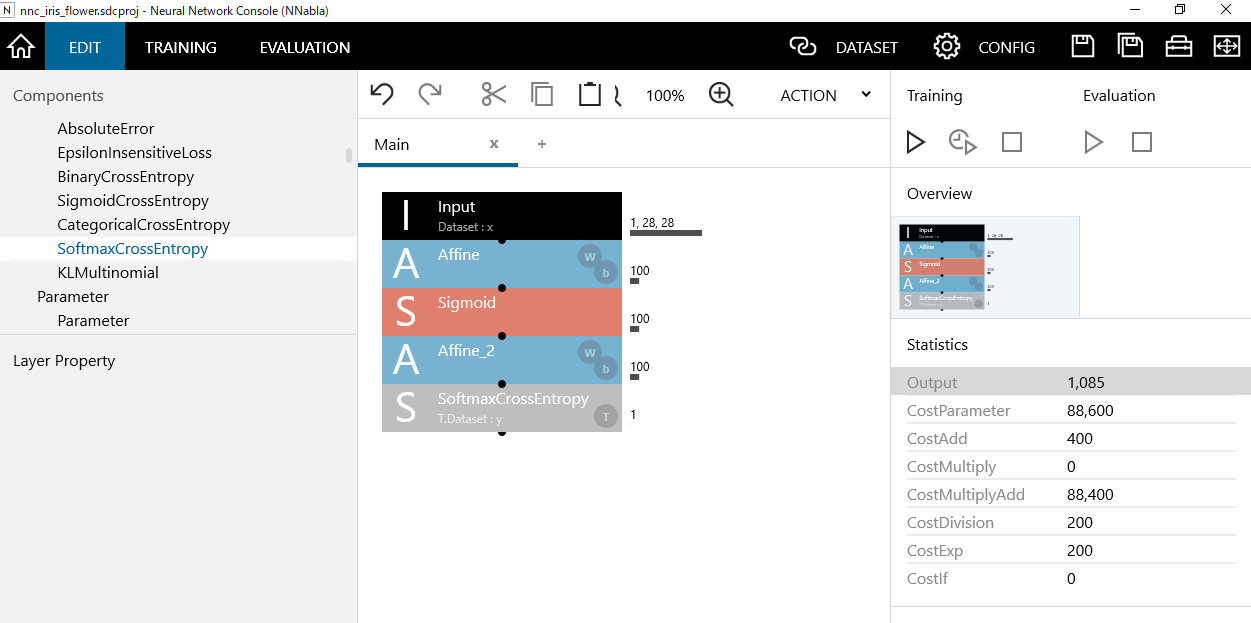
INPUT
defualtではInputのsizeに1,28,28が入力されています。
このsizeには入力するパラメータ数を設定するため4に修正します。
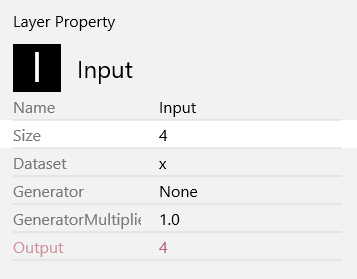
がく片の長さ(Sepal length)/がく片の幅(Sepal width)/花びらの長さ(Petal length)/花びらの幅(Petal width)の4つがINPUTとなることを示しています。
Affine(1回目)
defualtではAffineのOutShapeに100が入力されています。
この値を20に入力します。
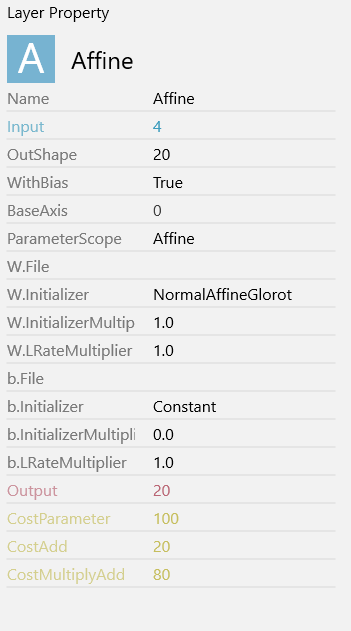
OutShapeは1つの層の深さを示しており、厳密にこの数字にしなければいけないというものはありません。経験や勘となります。ここのパラメータを調整することでいい結果が生まれたり、悪い結果となったりします。
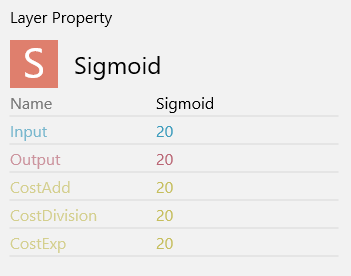
Sigmoid
defualtの設定のままで問題ありません。
先ほど、AffineのOutShapeを20に変更しているため、SigmoidのInput/Outputともに20に変更されています。
Affine(2回目)
AffineのOutShapeを3に変更します。
こちらのAffineは出力層となるため、最終的な出力の種類の数を入力します。
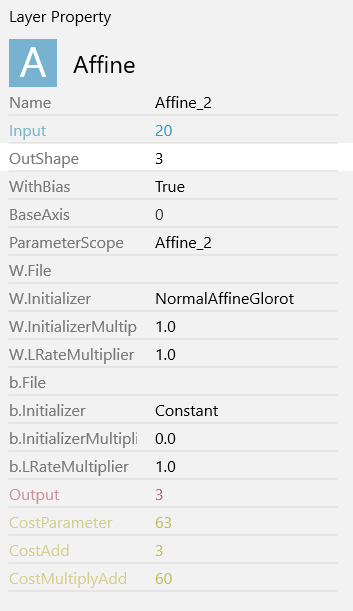
最終的な出力はVersicolou(ブルーフラッグ)/setosa(ヒオウギアヤメ)/Virginicaの3種類となるため、3を入力します。
SoftmaxCrossEntopy
defualtの設定のままで問題ありません。
Inputが3となっており、Outputが1となっていることに注目してください。
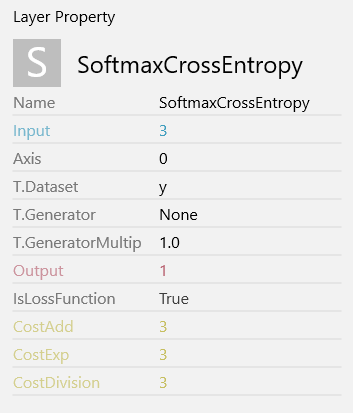
Inputの3は直前のAffineの出力が3となっているため、その数が引き継がれています。Outputについては、最終結果がアヤメの識別を0~2の数値のカテゴリとして表したものとなり、1桁で表示するため1となっています。
以上で試験の準備は完了です。次回は訓練・評価を実際に行っていきます。