
VGG16モデルを使用してオリジナル写真の画像認識を行う
今回はVGG16モデルを使用してオリジナルの写真の画像認識を行ってみたいと思います。
VGG16とは
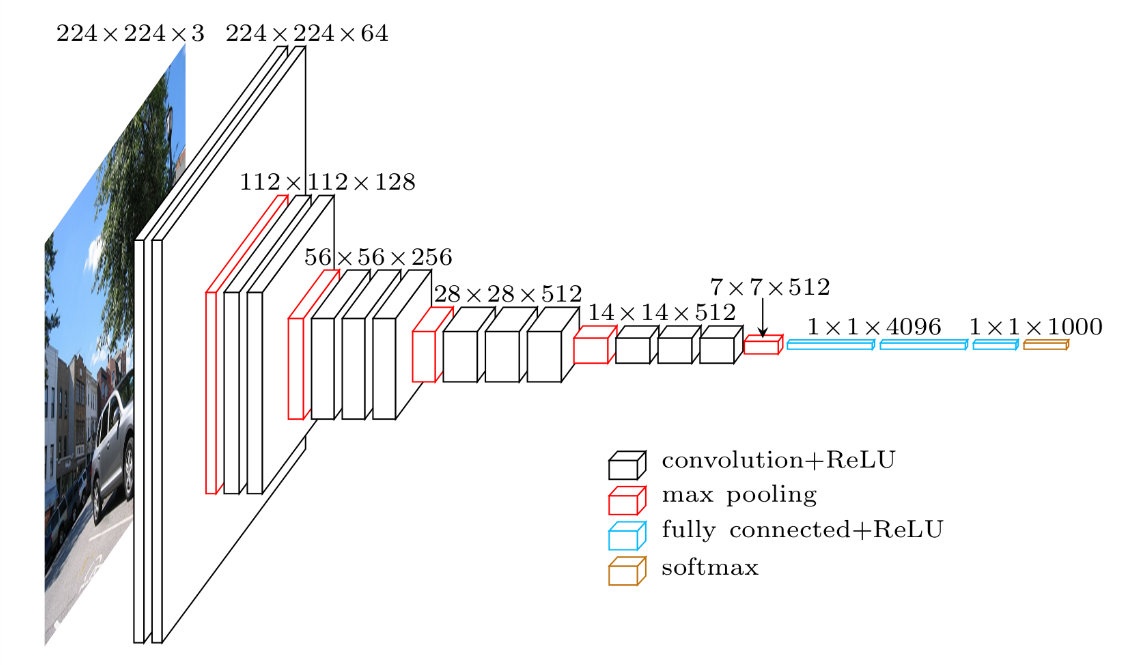
VGG16というのは,「ImageNet」と呼ばれる大規模画像データセットで学習された16層からなるCNNモデルです。Oxford大学の研究グループが提案し2014年のILSVRで好成績を収めました。16層からなるCNNモデルには、(224×224)の入力サイズのカラーチャネルの入力層と1000クラス分類の出力層を含み様々な研究に使用されています。
モデルイメージ
使用環境
- Google Colab
Python3 (GPU)
オリジナル画像
以下の3種類の写真(フリー画像)に対して画像認識を行っていきます。
フォルダ構成は以下の通りです
image
→bird.jpg
→cat.jpg
→lion.jpg
Google Colabにアップロードするためzipに圧縮しておきます
(ファイル名:image.zep)
ソースコード
INPUT画像のアップロード(ZIP形式)
|
1 2 3 4 |
#INPUT画像のアップロード(ZIP形式) # show upload dialog from google.colab import files uploaded = files.upload() |
アップロードしたZIP形式のファイルを解凍
|
1 2 |
#アップロードしたZIP形式のファイルを解凍 !unzip image |
|
1 2 3 4 |
Archive: image.zip inflating: image/bird.jpg inflating: image/cat.jpg inflating: image/lion.jpg |
必要なライブラリをインポート
|
1 2 3 4 |
#r必要なライブラリをインポート from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions from keras.preprocessing import image import numpy as np |
VGG16の読み出し
|
1 2 |
# VGG16の読み出し model = VGG16() |
|
1 2 3 4 5 |
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels.h5 553467904/553467096 [==============================] - 35s 0us/step |
読み出したVGG16のモデルの確認
|
1 2 |
# 読み出したVGG16のモデルの確認 model.summary() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 _________________________________________________________________ |
入力層のinput_1 (InputLayer)は224×224×3となっており、(224×224)の入力サイズのカラーチャネル(3)になっていることが分かります。出力層のpredictions (Dense) では1000となっており、1000クラスの分類になっていることが分かります。
INPUT画像を224 x 224にリサイズして画像の読み込み
|
1 2 3 4 |
# INPUT画像を224 x 224にリサイズして画像の読み込み img_bird = image.load_img('image/bird.jpg', target_size=(224, 224)) img_cat = image.load_img('image/cat.jpg' , target_size=(224, 224)) img_lion = image.load_img('image/lion.jpg' , target_size=(224, 224)) |
読み込んだ画像をarrayに変換
|
1 2 3 4 |
# 読み込んだ画像をarrayに変換 arr_bird = image.img_to_array(img_bird) arr_cat = image.img_to_array(img_cat) arr_lion = image.img_to_array(img_lion) |
画像をVGG16モデルの事前学習時と同じ状態に合わせて変換
|
1 2 3 4 |
# 画像をVGG16モデルの事前学習時と同じ状態に合わせて変換 arr_bird = preprocess_input(arr_bird) arr_cat = preprocess_input(arr_cat) arr_lion = preprocess_input(arr_lion) |
3次元テンソル(rows, cols, channels) を 4次元テンソル (samples, rows, cols, channels) に変換
|
1 2 3 |
# 3次元テンソル(rows, cols, channels) を 4次元テンソル (samples, rows, cols, channels) に変換 input = np.stack([arr_bird, arr_cat, arr_lion]) input.shape |
予測値を算出
|
1 2 3 4 |
# 予測値を算出 # 予想値は確率が高いTOP10を表示 preds = model.predict(input) results = decode_predictions(preds, top=10) |
画像認識結果
|
1 |
img_bird |

|
1 |
results[0] |
|
1 2 3 4 5 6 7 8 9 10 |
[('n01582220', 'magpie', 0.6588893), ('n01855672', 'goose', 0.11239987), ('n02018207', 'American_coot', 0.043373622), ('n01847000', 'drake', 0.029205887), ('n02058221', 'albatross', 0.018216735), ('n02025239', 'ruddy_turnstone', 0.010699745), ('n01806567', 'quail', 0.008205106), ('n01819313', 'sulphur-crested_cockatoo', 0.007657108), ('n01514859', 'hen', 0.007192487), ('n01580077', 'jay', 0.0070704473)] |
|
1 |
img_cat |

|
1 |
results[1] |
|
1 2 3 4 5 6 7 8 9 10 |
[('n02123045', 'tabby', 0.4234919), ('n02124075', 'Egyptian_cat', 0.12558442), ('n02097047', 'miniature_schnauzer', 0.122963406), ('n02086240', 'Shih-Tzu', 0.062026307), ('n02123159', 'tiger_cat', 0.036858775), ('n02098413', 'Lhasa', 0.027108844), ('n02094433', 'Yorkshire_terrier', 0.017841887), ('n02097209', 'standard_schnauzer', 0.014715143), ('n02113624', 'toy_poodle', 0.0115072625), ('n02123394', 'Persian_cat', 0.009284031)] |
|
1 |
img_lion |

|
1 |
results[2] |
|
1 2 3 4 5 6 7 8 9 10 |
[('n02129165', 'lion', 0.9999267), ('n02112137', 'chow', 2.1677808e-05), ('n02410509', 'bison', 1.9796138e-05), ('n02437312', 'Arabian_camel', 9.840998e-06), ('n02403003', 'ox', 7.513337e-06), ('n02117135', 'hyena', 7.410268e-06), ('n02486410', 'baboon', 1.099701e-06), ('n02132136', 'brown_bear', 1.0500808e-06), ('n02125311', 'cougar', 8.615237e-07), ('n02130308', 'cheetah', 7.798018e-07)] |
まとめ
VGG16のモデルを使用してオリジナルの画像認識を行いました。意外と簡単にできたのではないでしょうか。これらをアプリとして組み込むだけで簡単な画像認識ソフトが作れそうです。今回はVGG16のデフォルトとして入っている1000クラスの判定を行いましたが、次回は出力層を変化させ、自作の分類器を作成してみようと思います。