
機械学習でのクラスタリング分析(Clustering)とは
クラスタリング分析(Clustering)とは異なる性質のものが混ざり合った集団から、互いに似た性質を持つものをある規則・共通項に従って分類・グルーピングする手法のことです。
代表的な「教師なし学習」の一種となります。
「教師なし学習」の一種ということは、正解となるデータが存在しない状態でのモデル作成となり、コンピュータ自身が正解となるデータを求める学習法方法です。
この手法を用いて、記事やテキストの情報のカテゴリー分けを行ったり、商品のグルーピングをすることが出来るようになります。
Amazonなどで買い物をした場合、「あなたにお勧めの商品はこちらです」という言葉をよく見かけると思います。
これもクラスタリング分析を活用した一つです。
このようにビックデータの分析によく使用され、人間の目では思いもつかなかったカテゴリの分類を行うことができるようになります。
その結果、新たな客層に対したマーケティングを的確に行えるようになります。
このようなシステムはレコメンドシステムと呼ばれ様々なECサイトで使用されています。
クラスタリング分析の例
実際にクラスタリング分析の例を見てみましょう。
以下のような散布図があったとします。
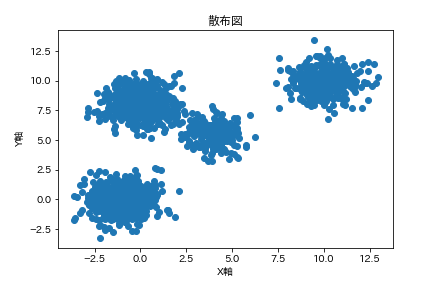
非階層型クラスタリング(K-means法(K平均法)を使用しクラスタリング分析(Clustering)を行っていきます。
クラスタリングが3つの場合
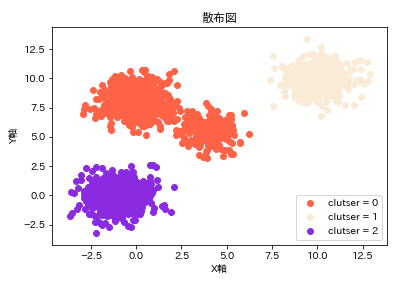
それぞれグループの色が青グループ、赤グループ、ピンクグループと3つに分かれています。
では次にクラスタリングを4つに増やした場合の例を見てみます。
クラスタリングが4つの場合
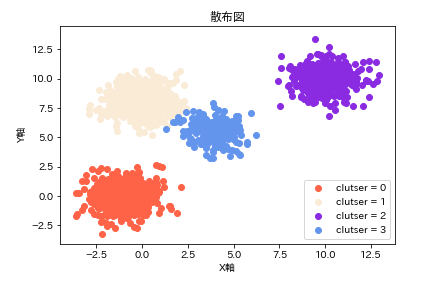
先ほどの1つのグループが分割して4つのグループに分かれています。
このようにコンピュータの力で自動的に行うのがクラスタリング分析(Clustering)となります。
今回、クラスタリングが3つの場合とクラスタリングが4つの場合に分けたのは一つ理由があります。
非階層型クラスタリング(K-means法(K平均法)の場合は、クラスタリングの数をユーザが決定しなければいけません。
つまり、クラスタリングとして何個のグループを作成するのかは、ユーザが与える必要があります。自動的に決定されるわけではないのです。
そのためユーザはデータを観察して、何個のグループに分けるのが適切かを考えなければいけません。
また、非階層型クラスタリング(K-means法(K平均法)の場合は、単純に距離でグループ分けをしています。
グループの中心となる点をまず初めに決定し、お互いに近い点を同一グループとして割り当てられます。
このようにしてグルーピング分けが行われます。
非階層型クラスタリング(K-means法(K平均法)の特徴の一つとして、クラスタリングの数をユーザが決定する必要がありました。
そして、距離でグループ分けを行っていました。
クラスタリング分析(Clustering)は様々な種類が存在し、クラスタリングの数を自動的に算出してくれるものや、距離以外でグルーピング分けを行うものが多数あります。
非階層型クラスタリング(K-means法(K平均法)以外のクラスタリングの種類としては、階層型クラスタリング(AGNES)、スペクトラムクラスタリング、自己組織化マップ(SOM)などが存在しますので、興味のある方は調べてみてください。