スケーリングとは何か
統計や機械学習で扱うデータ分析の前処理では"正規化"や"標準化"がよく使用されます。
"正規化"や"標準化"を行っておらず、体重、身長、年齢など複数の異なる特徴量をそのまま扱ってしまうと尺度が異なってしまうため、うまく学習できない場合があります。そこでデータをある基準に沿って変換し尺度を統一することが必要です。この尺度を統一することをスケーリングと呼びます。
スケーリングは"正規化"や"標準化"の種類があります。
"正規化"はMin-Max normalization"、標準化"はstandardizationもしくはz-score normalizationと呼ばれます。
このページで解説する内容
- 正規化の特徴
- 標準化の特徴
- sikit-learnを使用した正規化のコード
- sikit-learnを使用した標準化のコード
正規化の特徴
特徴量の値の範囲を一定の範囲におさめる変換です。主に[0, 1]か、[-1, 1]の範囲内に収めます。最大値と最小値が予め決まっている場合や、データの分布が一様分布である場合に有効です。しかし、外れ値が存在する場合はデータが偏ってしまうので注意が必要です。
標準化の特徴
データを平均0、標準偏差が1になるように変換する正規化法です。最大値と最小値が予め決まっていない場合や、外れ値のあるデータに対して有効です。
実際にsikit-learnにて提供されているデータ(ボストン市の住宅価格)をベースにスケーリングを行い結果を見てみます。
ソースコード
事前準備
|
1 2 3 4 5 6 |
#事前準備 import pandas as pd from sklearn.datasets import load_boston data = load_boston() data_df = pd.DataFrame(data.target) data_df.columns = ['Prime'] |
スケーリングを行っていない生データ
|
1 |
data_df.describe() |
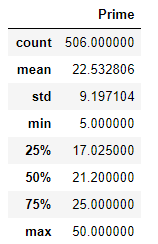
mean(平均値)・・・22.532806
std(標準偏差)・・・9.197104
min(最小値)・・・5.000000
max(最大値)・・・50.000000
となっています。
正規化を行ったデータ
|
1 2 3 4 5 6 |
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler([-1,1]) scaler.fit(data_df) data_MinMaxScaler = scaler.transform(data_df) |
|
1 2 3 |
data_MinMaxScaler = pd.DataFrame(data_MinMaxScaler) data_MinMaxScaler.columns = ['Prime'] data_MinMaxScaler.describe() |
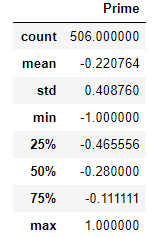
mean(平均値)・・・-0.220764
std(標準偏差)・・・0.408760
min(最小値)・・・-1.000000
max(最大値)・・・1.000000
となっています。
指定された最小値、最大値の間でスケーリングされています。
また、単一のデータのみならず複数のデータについても同じ方法でスケーリングをすることが出来ます。
以下は別なデータを使用した場合の例です。
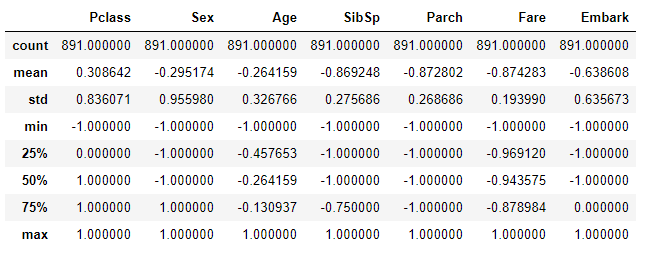
標準化を行ったデータ
sklearnのライブラリで提供されているStandardScalerを使用することで標準化することが出来ます。StandardScalerには引数がなく、そのまま使用することで平均 0 標準偏差 1にスケーリングされます。データフレーム(ここではdata_df)をfitしてtransformを行うことで標準化されたデータを使用することが出来ます。
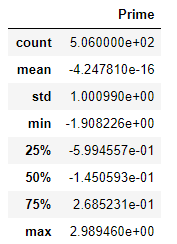
mean(平均値)・・・-4.247810e-16
std(標準偏差)・・・1.000990e+00
min(最小値)・・・-1.908226e+00
max(最大値)・・・2.989460e+00
となっています。
eがついているため見えにくいですが、-4.247810×10-16なのでほぼ平均が0となっています。
また、単一のデータのみならず複数のデータについても同じ方法でスケーリングをすることが出来ます。
以下は別なデータを使用した場合の例です。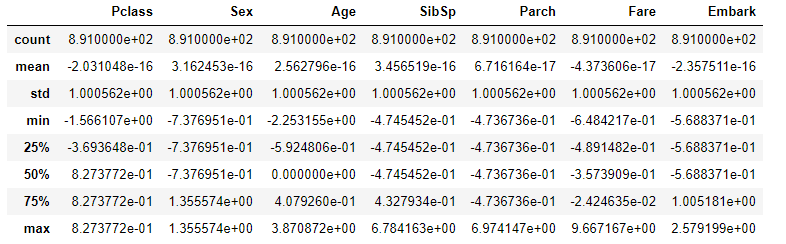
まとめ
統計や機械学習では複数の異なる特徴量をそのまま扱ってしまうと尺度が異なってしまうため、扱うデータ分析の前処理では"正規化"や"標準化"が必要です。sklearnのライブラリを使用することで簡単に"正規化"や"標準化"を実現をすることができるため是非活用してください。