KaggleチュートリアルTitanicでスケーリング(標準化や正規化)や識別子(サポートベクターマシン、K近傍法など)を組み合わせた場合、どのような結果になるのだろうと疑問に思ったので実際に試してみました。
kaggleとは
「Kaggle(カグル)」とは2010年にアメリカで設立された世界中の企業や研究者がデータを投稿する世界最大のデータ分析のコンペティションです。現在、60万人以上のデータサイエンティストが登録していると言われ、世界各国のデータサイエンティストがその分析モデルを競い合っています。コンペティションには賞金が設定されているものもあり、上位者には賞金やメダルが授与されます。賞金には高額なものも多く、数百万円から億単位のものまであります。また、コンペティションに使用したソースコードが公開されているものもあり、上位入賞者のコードを読むことで、データサイエンスやAIの分野において必要なスキルを身につけることが出来ます。
Kaggleの中でも特に有名な課題として「Titanic : Machine Learning from Disaster」(タイタニック号の生存者予測)があります。Kaggleのチュートリアルコンペとして用意されており、性別、チケットクラスなどの乗客員データから、生存の予測精度を競い合います。
公式サイト
https://www.kaggle.com/c/titanic
実施した組み合わせ
以下のスケーリング3種類と識別子7種類の組み合わせ合計21種類を実施
スケーリング
- スケーリングなし
- StandardScaler(標準化)
- MinMaxScaler (正規化)
識別子
- SVC(サポートベクターマシン RBFカーネル)
- SVC(サポートベクターマシン 線形カーネル)
- KNeighborsClassifier(K近傍法)
- LogisticRegression(ロジスティック回帰)
- Perceptron(パーセプトロン)
- MLPClassifier(ニューラルネットワーク)
- RandomForestClassifier(ランダムフォレスト)
使用したデータ
オリジナルのデータに対して以下の変更を加えています。
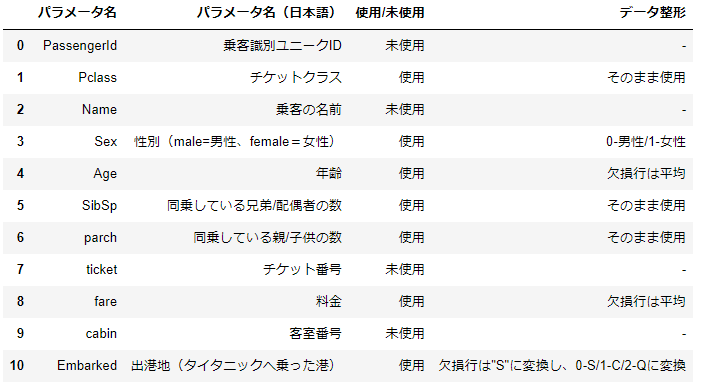
未使用データの扱い
以下の理由により今回は未使用のデータにしました。
- PassengerId(乗客識別ユニークID) ・・ID番号のため生存データへの影響はなしと想定
- Name(乗客の名前)・・名前のため生存データに影響しないと想定
- ticket(チケット番号)・・チケット番号のため生存データへの影響はなしと想定
- cabin(客室番号)・・訓練データが204と少なすぎるためパラメータ自体を削除
本当に影響が無いのかどうかは分析をする必要があります。
ただし、今回は影響が無いという前提で行っていきます。
欠損値の扱い
欠損値については、以下のように補完しています。
- Age(年齢)・・平均
- fare(料金)・・平均
- Embarked(出港地)・・欠損行は"S"に変換
オブジェクト型の扱い
オブジェクト型については、以下のように数値に変換しています。
- Sex(性別)・・0-男性/1-女性
- Embarked(出港地)・・0-S/1-C/2-Qに変換
スケール変換
今回は3種類のスケール変換で実施してみます。
- スケーリングなし
- StandardScaler(標準化)
- MinMaxScaler (正規化)
スケーリングなし
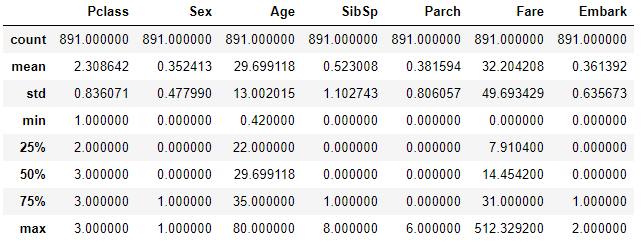
何もスケーリングしていないので、平均値や標準偏差がパラメータ毎に違っています
StandardScaler(標準化)
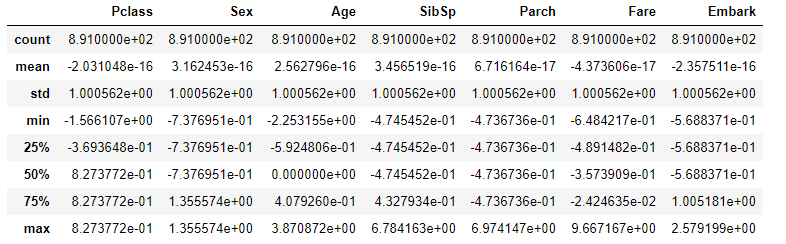
全てのデータを平均 0 標準偏差 1になるように標準化しています。
標準化するためにscikit-learnのStandardScalerを使用しています。
MinMaxScaler (正規化)
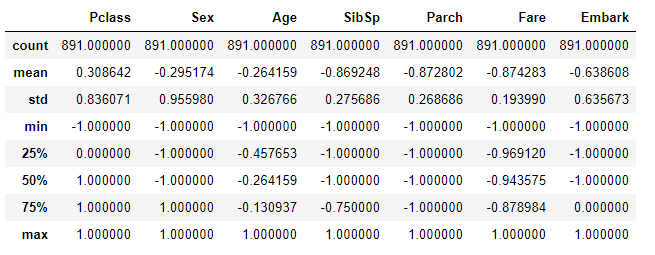
全てのデータの最小が 0 最大 1になるように正規化しています。
正規化するためにscikit-learnのMinMaxScalerを使用しています。
識別子
今回は以下の識別子を使用してみました
- SVC(サポートベクターマシン RBFカーネル)
- SVC(サポートベクターマシン 線形カーネル)
- KNeighborsClassifier(K近傍法)
- LogisticRegression(ロジスティック回帰)
- Perceptron(パーセプトロン)
- MLPClassifier(ニューラルネットワーク)
- RandomForestClassifier(ランダムフォレスト)
また、共通点として以下の設定を行っています。
- Cross-validation(交差検証)は3とする
- ハイパーパラメータの調整としてgrid search(グリッドサーチ)を使用
- 乱数シードがある場合としてrandom_state=3を使用
SVC(サポートベクターマシン RBFカーネル)
以下の条件で高性能が出たパラメータについて実施しています。
- Costパラメータ(C)について 2-10~210 の範囲でgrid search(グリッドサーチ)を使用
- 乱数シードとしてrandom_state=3を使用
- Cross-validation(交差検証)は3
スケーリングなし
|
1 2 3 4 |
SVC(C=10.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=3, shrinking=True, tol=0.001, verbose=False)) |
StandardScaler(標準化)
|
1 2 3 4 |
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=3, shrinking=True, tol=0.001, verbose=False)) |
MinMaxScaler (正規化)
|
1 2 3 4 |
SVC(C=10.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf', max_iter=-1, probability=False, random_state=3, shrinking=True, tol=0.001, verbose=False)) |
SVC(サポートベクターマシン 線形カーネル)
以下の条件で高性能が出たパラメータについて実施しています。
- Costパラメータ(C)について 2-10~210 の範囲でgrid search(グリッドサーチ)を使用
- Cross-validation(交差検証)は3
スケーリングなし
|
1 2 3 4 |
SVC(C=0.1, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)) |
StandardScaler(標準化)
|
1 2 3 4 |
SVC(C=0.1, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)) |
MinMaxScaler (正規化)
|
1 2 3 4 |
SVC(C=0.01, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)) |
KNeighborsClassifier(K近傍法)
以下の条件で高性能が出たパラメータについて実施しています。
- n_neighborsについて1~19の範囲でgrid search(グリッドサーチ)を使用
- Cross-validation(交差検証)は3
スケーリングなし
|
1 2 3 |
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=15, p=2, weights='uniform')) |
StandardScaler(標準化)
|
1 2 3 |
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=12, p=2, weights='uniform')) |
MinMaxScaler (正規化)
|
1 2 3 |
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=8, p=2, weights='uniform')) |
LogisticRegression(ロジスティック回帰)
以下の条件で高性能が出たパラメータについて実施しています。
- Costパラメータ(C)について 10-10~1010 の範囲でgrid search(グリッドサーチ)を使用
- 乱数シードとしてrandom_state=3を使用
- Cross-validation(交差検証)は3
スケーリングなし
|
1 2 3 4 |
LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=3, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)) |
StandardScaler(標準化)
|
1 2 3 4 |
LogisticRegression(C=10.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=3, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)) |
MinMaxScaler (正規化)
|
1 2 3 4 |
LogisticRegression(C=0.01, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=3, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)) |
Perceptron(パーセプトロン)
以下の条件で高性能が出たパラメータについて実施しています。
- alphaについて 10-10~1010 の範囲でgrid search(グリッドサーチ)を使用
- 乱数シードとしてrandom_state=3を使用
- Cross-validation(交差検証)は3
スケーリングなし
|
1 2 3 |
Perceptron(alpha=1e-10, class_weight=None, eta0=1.0, fit_intercept=True, max_iter=None, n_iter=None, n_jobs=1, penalty=None, random_state=3, shuffle=True, tol=None, verbose=0, warm_start=False)) |
StandardScaler(標準化)
|
1 2 3 |
Perceptron(alpha=1e-10, class_weight=None, eta0=1.0, fit_intercept=True, max_iter=None, n_iter=None, n_jobs=1, penalty=None, random_state=3, shuffle=True, tol=None, verbose=0, warm_start=False)) |
MinMaxScaler (正規化)
|
1 2 3 |
Perceptron(alpha=1e-10, class_weight=None, eta0=1.0, fit_intercept=True, max_iter=None, n_iter=None, n_jobs=1, penalty=None, random_state=3, shuffle=True, tol=None, verbose=0, warm_start=False)) |
MLPClassifier(ニューラルネットワーク)
以下の条件で高性能が出たパラメータについて実施しています。
- ニューラルネットワークを以下のように設定
- 乱数シードとしてrandom_state=3を使用
- Cross-validation(交差検証)は3
|
1 2 3 4 5 6 7 8 9 10 11 |
ニューラルネットワーク param = {'hidden_layer_sizes': [ (10,), (100,), (10,),(50,), (10,), (50,), (100,), (10,10,), (50,50,), (100,100,), (10, 5,), (5,5,), (30, 20, 10), (100,1000,50,), (1000,100,50,), (10,10,10), (50,50,50), (100,100,100,), ]} |
スケーリングなし
|
1 2 3 4 5 6 7 |
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9, beta_2=0.999, early_stopping=False, epsilon=1e-08, hidden_layer_sizes=(30, 20, 10), learning_rate='constant', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True, power_t=0.5, random_state=3, shuffle=True, solver='adam', tol=0.0001, validation_fraction=0.1, verbose=False, warm_start=False))にゅ |
StandardScaler(標準化)
|
1 2 3 4 5 6 7 |
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9, beta_2=0.999, early_stopping=False, epsilon=1e-08, hidden_layer_sizes=(100,), learning_rate='constant', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True, power_t=0.5, random_state=3, shuffle=True, solver='adam', tol=0.0001, validation_fraction=0.1, verbose=False, warm_start=False)) |
MinMaxScaler (正規化)
|
1 2 3 4 5 6 7 |
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9, beta_2=0.999, early_stopping=False, epsilon=1e-08, hidden_layer_sizes=(50, 50), learning_rate='constant', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True, power_t=0.5, random_state=3, shuffle=True, solver='adam', tol=0.0001, validation_fraction=0.1, verbose=False, warm_start=False)) |
RandomForestClassifier(ランダムフォレスト)
以下の条件で高性能が出たパラメータについて実施しています。
- max_depthについて1~19、n_estimatorsについて1~19の範囲でgrid search(グリッドサーチ)を使用
- 乱数シードとしてrandom_state=3を使用
- Cross-validation(交差検証)は3
スケーリングなし
|
1 2 3 4 5 6 |
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=7, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=14, n_jobs=1, oob_score=False, random_state=3, verbose=0, warm_start=False)) |
StandardScaler(標準化)
|
1 2 3 4 5 6 |
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=7, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=14, n_jobs=1, oob_score=False, random_state=3, verbose=0, warm_start=False)) |
MinMaxScaler (正規化)
|
1 2 3 4 5 6 |
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=7, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=14, n_jobs=1, oob_score=False, random_state=3, verbose=0, warm_start=False)) |
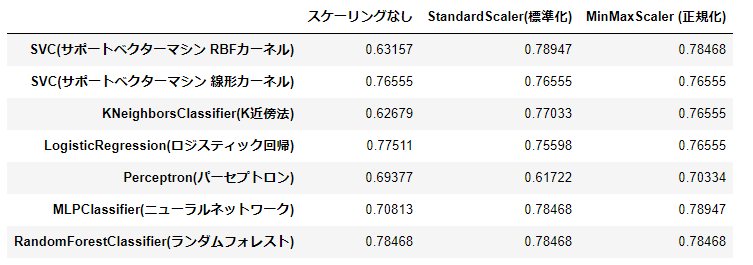
正答率
Kaggleへ投稿した結果、正答率は以下の通りとなりました。
61.722%~78.947%の正答率となりました。様々な組み合わせを実施した割りに80%を超すものが一個もありませんでした。
正答率が低かったもの
- 61.722%
- Perceptron(パーセプトロン)+StandardScaler(標準化)
正答率が高かったもの
- 78.947%
- SVC(サポートベクターマシン RBFカーネル)+StandardScaler(標準化)
- MLPClassifier(ニューラルネットワーク)+MinMaxScaler (正規化)
正答率の統計データを眺めてみる
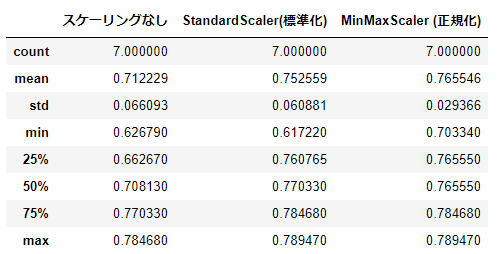
こうして見ると「スケーリングなし」よりはStandardScaler(標準化)やMinMaxScaler (正規化)のスケーリングをしたほうが平均点が高くなっています。また、MinMaxScaler (正規化)はブレ幅が少なくある一定以上の成績を出しています。とは言ってもこれはデータの特長量の選択やハイパーパラメータの設定値により変更してくるものなので今回は一例であり必ずしもそうなるというわけではありません。
まとめ
今回はスケーリング3種類と識別子7種類の組み合わせでkaggleの「Titanic : Machine Learning from Disaster」(タイタニック号の生存者予測)を行ってみました。正答率は61.722%~78.947%になりました。80%をこさなかったのは残念ですが、初めの段階でName(乗客の名前)やcabin(客室番号)を未使用データとして扱ってしまったのが一つの原因かなと思います。
今回いろいろな発見がありました。
例えばRandomForestClassifier(ランダムフォレスト)を利用した場合、スケーリングの有無に限らずに結果は変わらない。性質を考えれば当然かもしれないですが改めて実測できたので良かったかなと思います。他にPerceptron(パーセプトロン)はハイパーパラメータは変わってなくともスケーリングの有無により結果が変わってきています。
まだまだ機械学習やAIについては実際にやるまでは結果が分からないということが多いので、今後も引き続き試していきたいと思います。
みなさんも是非いろいろなケースでチャレンジしてください。