SonyのNNCで人工知能を試してみる(02_binary_cnn.sdcproj)
SonyのNNC(Neural Network Console)はプログラミングなしでディープランニングを実装できるツールであり、ソニーのグループ会社のソニーネットワークコミュニケーションズ社からリリースされています。クラウド版、Windowsアプリ版がありどちらも無料で使用することが出来ます。クラウド版にはファイル容量 10GB、使用可能時間 10H、プロジェクト数 10Pと制限はありますが、インストールは不要であり、WEBにアクセス可能ならばWindowsに限らずにLinux、Mac OSなどOSに関わらず利用することができます。Windowsアプリ版はWindows8.1以上の64ビットOSが必要となりますが使用に制限はありません。
今回はSonyのNNCに付随されているサンプルの一つであるbinary_cnn.sdcprojを用いて簡単な人工知能を試してみます。
02_binary_cnn.sdcprojの概要
学習用データ、評価用データについては01_logistic_regressionと同様です。手書きの数字4、9が書かれた28×28ピクセルの画像を識別します。学習用データが1500個、評価用データが500個で構成されています。01_logistic_regressionとの差分として前回はロジスティック回帰を用いて学習していたところ、今回はCNNと呼ばれるディープランニングを使用しています。CNNを用いることでより精度が高い識別を行うことが可能となります。
プロジェクトを開く
クラウド版の場合はNNC(Neural Network Console)のURLを入力、Windowsアプリ版の場合は”neural_network_console.exe”をダブルクリックすることでNNCのホームが立ち上がります。左上の家の形をしたホームボタンを選択し、02_binary_cnn.sdcprojをクリックすることでプロジェクトが開きます。
前回の01_logistic_regressionでダウンロードされていた場合はすでに手書き画像はダウンロードされているため、すぐに実行することが出来ます。初回の場合は手書き画像のデータセットのダウンロードが自動で開始されるため完了するまでしばらく待ちましょう。
Components画面
プロジェクトを開いた直後はComponentsの画面が表示されています。入力層、中間層、出力層から成り立っています。今回はCNNのディープランニングを用いるので、畳み込み層、プーリング層が入っています。畳み込み層、プーリング層は2セット存在します。
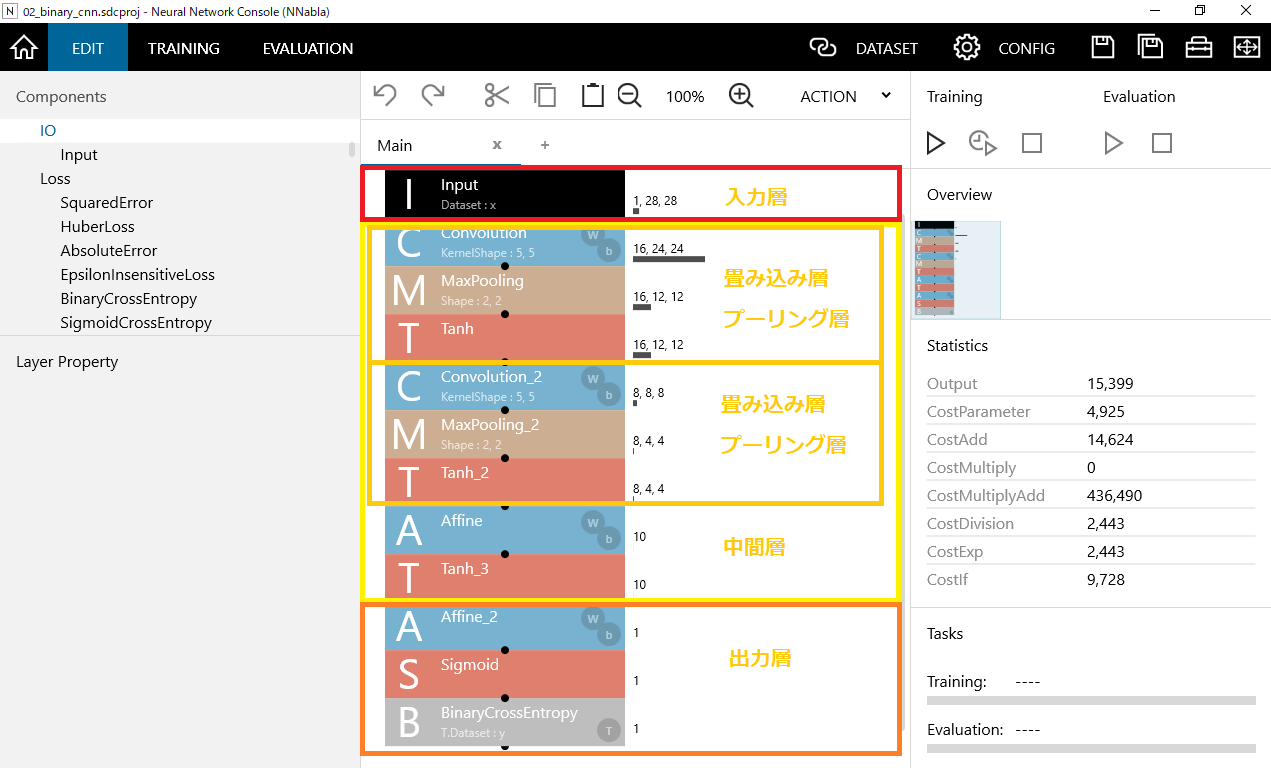
入力層:24×24の16ノードから成り立っています。
畳み込み層1回目:24×24の16ノードから成り立っています。
プーリング層1回目:12×12の16ノードから成り立っています。
畳み込み層2回目: 8×8の8ノードから成り立っています。
プーリング層2回目: 4×4の8ノードから成り立っています。
出力層: 1ノードから成り立っています。
前回同様、出力層はAffine(全結合)、Sigmod(シグモイド関数)、BinaryCrossEntropy(交差エントロピー)の要素から成り立っています。
学習用データ、評価用データの確認
右上のDATASETボタンをクリックすることで、学習用データ、評価用データの中身を確認することが出来ます。
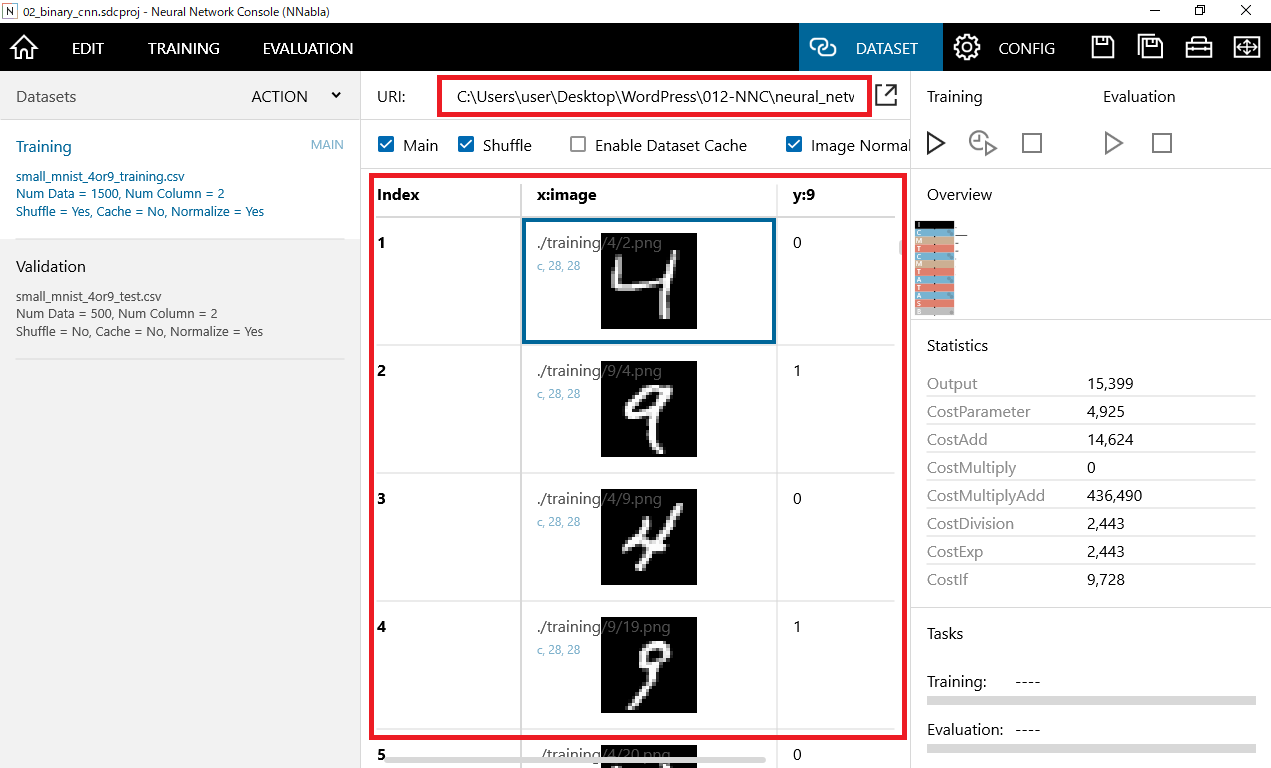
左窓のTrainingは「学習用データ」、Validationは「評価用データ」となっています。
学習用データはIndex,X:image,y:9の3つの変数で構成されています。Indexには画像の連番が格納されており、X:imageには画像データが格納されています。y:9には画像が9の数字であれば"1"が格納されており、4の数字であれば"0"が格納されています。
実際のデータを直接見たいという場合は、データが格納されているURLにアクセスすることで見ることができます。
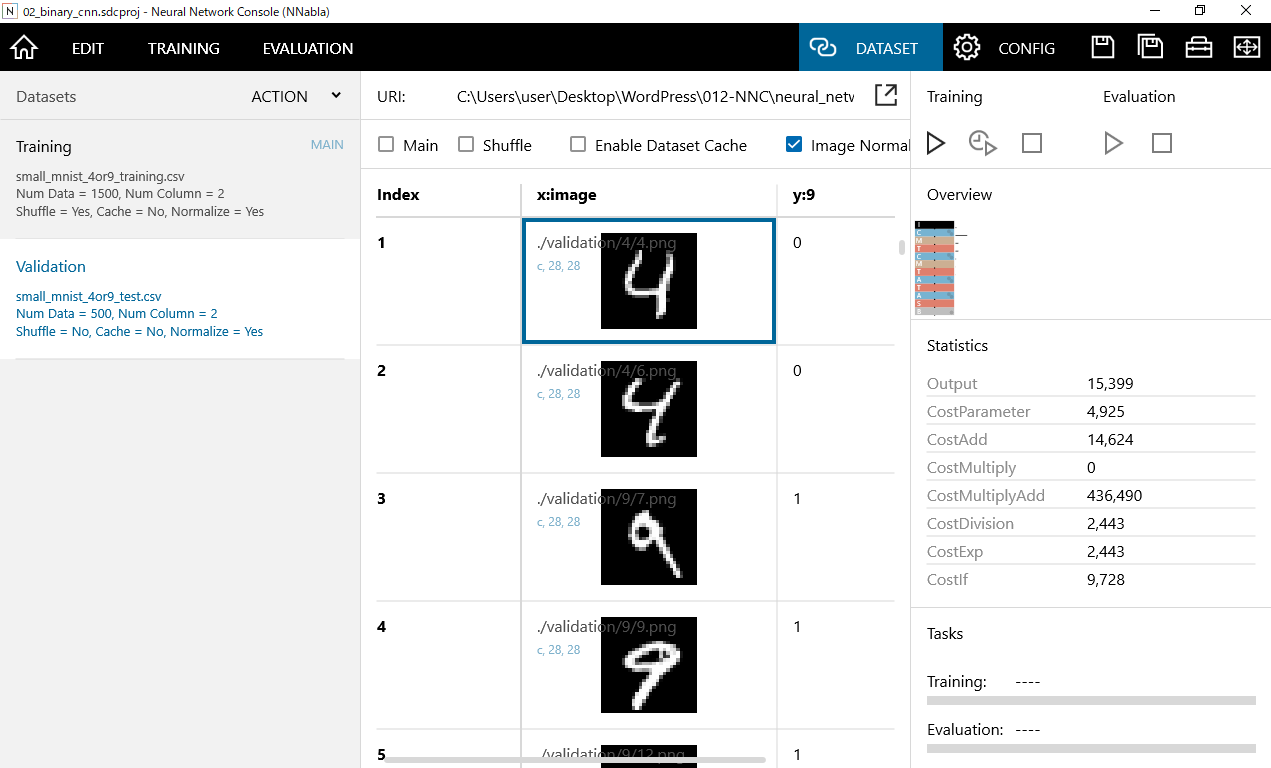
評価用データについても同様にIndex,X:image,y:9の3つの変数で構成されています。
Configの確認
DATASETボタンの右隣にあるConfigボタンをクリックすることで全体的な条件を確認することが出来ます。
注目すべきはMax EpochとBatch Sizeです。
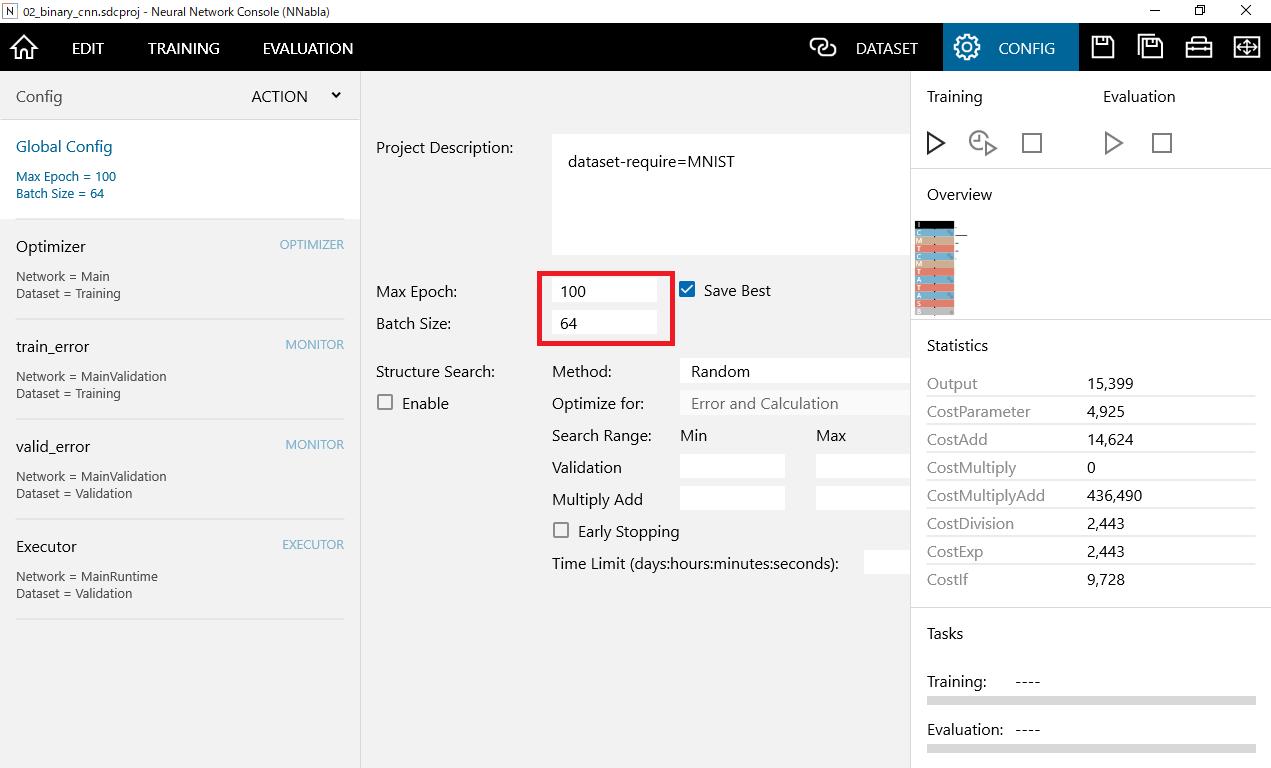 Max Epochはエポック数を示し、学習回数を設定します。今回は100が設定されています
Max Epochはエポック数を示し、学習回数を設定します。今回は100が設定されています
Batch Sizeはミニバッチ学習に使用するデータサイズとなります。今回は64となります。
エポック数とバッチサイズの関係性は次の通りです。
初めに全データの1500個に対してバッチサイズ数の単位で試験を実施します。具体的には1500個のデータのうち32個をまとめて実施。その後に別の32個分の試験を実施・・を繰り返していき1500個分全てのデータに対して試験を実施します。それを1エポックとしてエポック数分、つまり100回繰り返します。
このようにバッチサイズ単位で繰り返し試験を行うごとに重みを修正していきモデルの精度を高めていきます。
トレーニングの開始
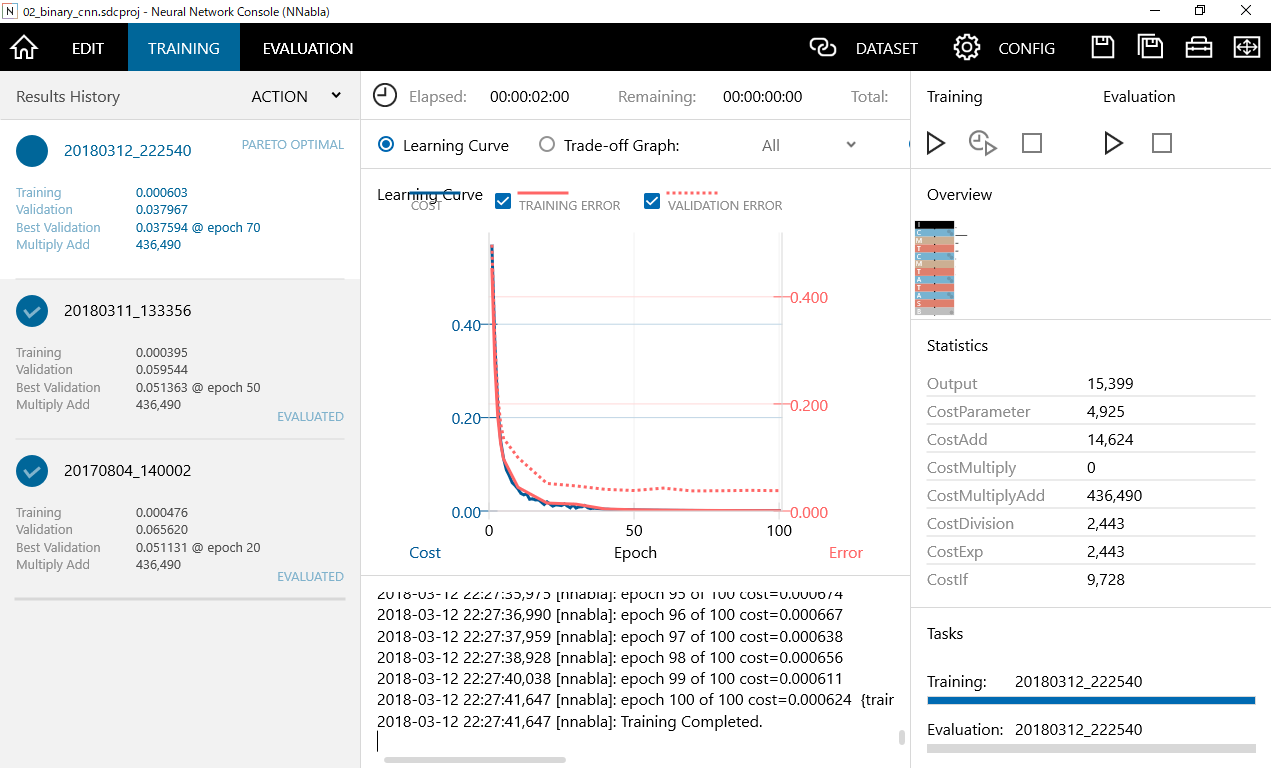
右窓のTrainingの右三角の矢印をクリックすることで、トレーニングが開始されます。トレーニングの回数は先ほどConfigで設定したMax EpochとBatch Sizeにしたがい行われます。学習が終了するまで待ちましょう。ロジスティック回帰の場合は比較的早く完了しますが、CNNを用いた場合は3分程度時間がかかります。
学習が終了したら下記のような学習結果が出力されます。繰り返し学習することでCOSTが少なくなってくるのが分かります。ロジスティック回帰の場合と比較してみるとほとんどCOSTが無いことが分かります。
評価の開始
右窓のEvaluationの右三角の矢印をクリックすることで、トレーニングが開始されます。評価用データが500個について手書き画像の識別を行っています。評価が終了するまで待ちましょう。
評価の結果
左上のEVALUATIONをクリックすることで評価の結果を見ることができます。
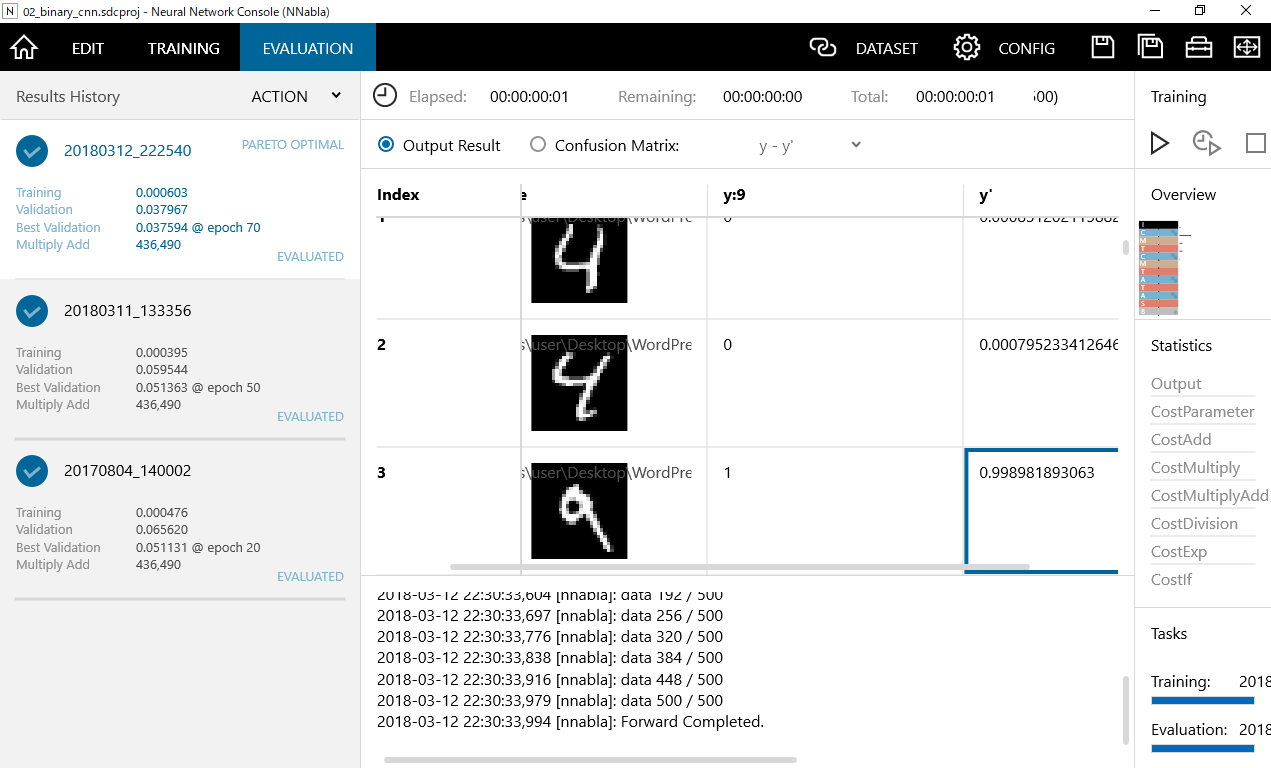
Index,X:image,y:9,y'の4つの変数で構成されています。Indexには画像の連番が格納されており、X:imageには画像データが格納されています。y:9には正解値のラベルが入っており、画像が9の数字であれば"1"、4の数字であれば"0"が格納されています。
y'については実際に評価した場合の9である確率値を示しており、1に近ければ近いほど9である確率が高いことをしめしています。画像でのINDEX3の場合は99%の確率となっています。
混同行列(Confusion Matrix)をクリックすることでクロス表を見ることができます。
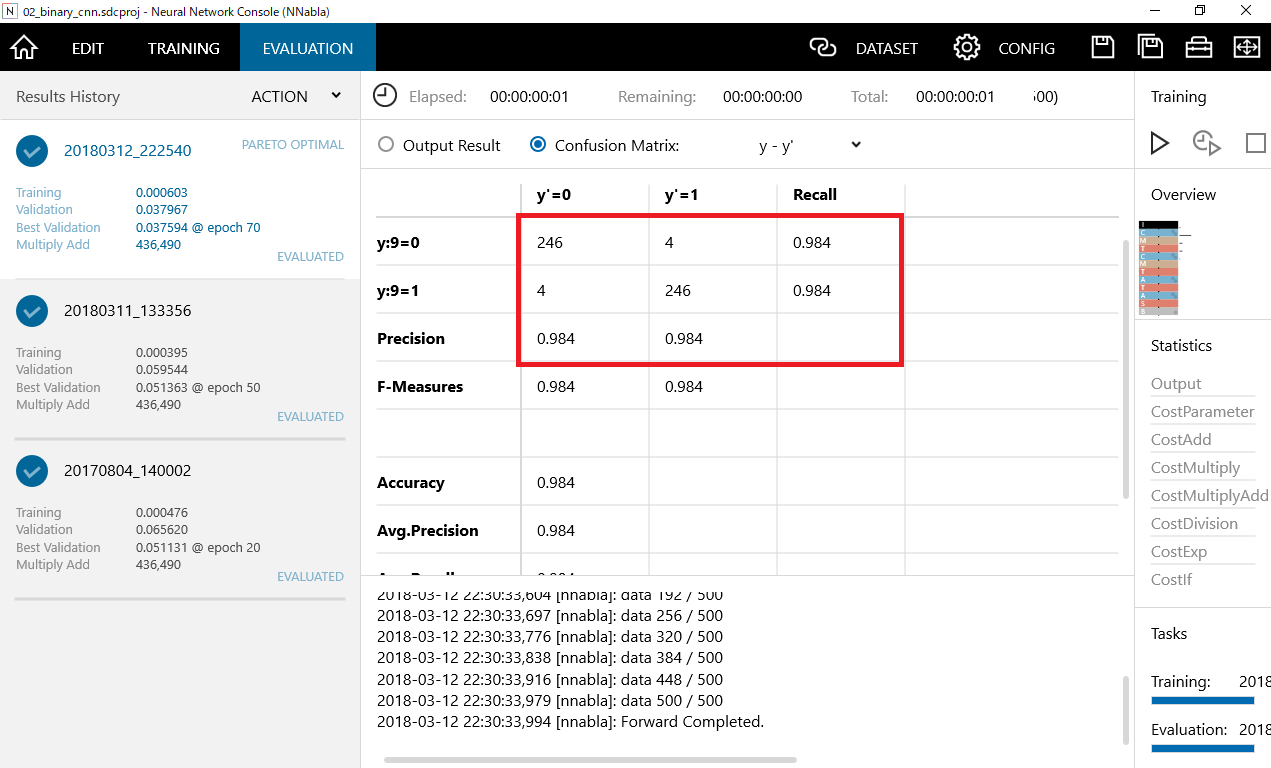
y:9=0 正解値が4のデータとなります。246個が正解し、4個が誤って9と判定されています。
98.4%の正解率となります。
前回のロジスティック回帰と比較してみます。
ロジスティック回帰: 239個が正解、11個が誤って9と判定 95.6%の正解率
CNN: : 246個が正解、4個が誤って9と判定 98.4%の正解率
y:9=1 正解値が9のデータとなります。237個が正解し、13個が誤って4と判定されています。
ロジスティック回帰: 237個が正解、13個が誤って9と判定 94.8%の正解率
CNN: : 246個が正解、4個が誤って9と判定 98.4%の正解率
全体の正解率はAccuracyで確認することができます。
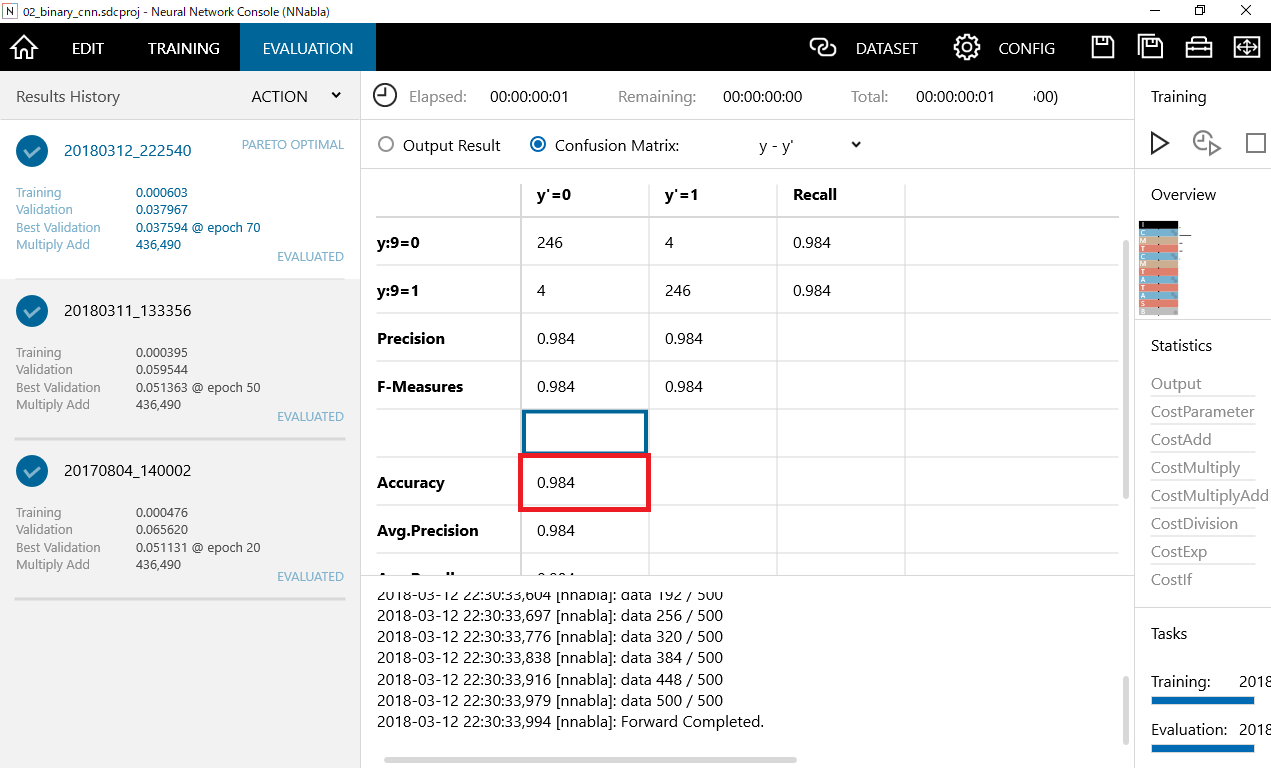
今回は98.4%でした。
ロジスティック回帰: 95.2%の正解率
CNN: : 98.4%の正解率
以上の結果よりディープランニングを用いた測定の方が精度が高いことが分かります。