物体検出とは
画像を推定する場合、大きく画像認識と物体検出に分かれます。
画像認識は1枚の画像を与え、それが「何」かを推定するもので、顔認証や文字認証などがあります。顔認証では「映っている顔写真は男性か女性か」や「推定年齢」を判別し、文字認証では「手書き文字は0~9のどの数字」かを推定します。
それに対して、物体検出とは1枚の画像に1つ以上の物体が映っており、「何」だけではなく、それが「どこ」にあるのかについても推定します。大きな違いとして、「複数の物体を検出できる点」と、その物体が「どこにあるか」を推定することが出来る点です。
このため、「車」の側で遊んでいる「子供」か、「車」の中にいる「子供」かを区別することができ、炎天下の中での車中置き去りを防止することも可能となります。
物体検出の有名どころでは「SSD」と「yolo」があります。
今回は「yolo」のFrameworkであるDarkneを用いて物体検出を行っています。
Darkneの実行方法
Darknetのインストール
|
1 |
git clone https://github.com/pjreddie/darknet |
|
1 2 3 4 5 |
Cloning into 'darknet'... remote: Counting objects: 5833, done. remote: Total 5833 (delta 0), reused 0 (delta 0), pack-reused 5832 Receiving objects: 100% (5833/5833), 6.04 MiB | 9.84 MiB/s, done. Resolving deltas: 100% (3914/3914), done. |
ディレクトリの移動
|
1 |
cd darknet |
makeコマンドの実行
|
1 2 |
Makefile GPU=1 |
|
1 |
make |
学習済みのモデルのダウンロード
|
1 |
wget http://pjreddie.com/media/files/yolo.weights |
実行
|
1 |
./darknet detect cfg/yolov2.cfg yolo.weights data/person.jpg |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs 1 max 2 x 2 / 2 416 x 416 x 32 -> 208 x 208 x 32 2 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BFLOPs 3 max 2 x 2 / 2 208 x 208 x 64 -> 104 x 104 x 64 4 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs 5 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BFLOPs 6 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BFLOPs 7 max 2 x 2 / 2 104 x 104 x 128 -> 52 x 52 x 128 8 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 9 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BFLOPs 10 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs 11 max 2 x 2 / 2 52 x 52 x 256 -> 26 x 26 x 256 12 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 13 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 14 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 15 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BFLOPs 16 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BFLOPs 17 max 2 x 2 / 2 26 x 26 x 512 -> 13 x 13 x 512 18 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 19 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 20 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 21 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BFLOPs 22 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BFLOPs 23 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024 3.190 BFLOPs 24 conv 1024 3 x 3 / 1 13 x 13 x1024 -> 13 x 13 x1024 3.190 BFLOPs 25 route 16 26 conv 64 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 64 0.044 BFLOPs 27 reorg / 2 26 x 26 x 64 -> 13 x 13 x 256 28 route 27 24 29 conv 1024 3 x 3 / 1 13 x 13 x1280 -> 13 x 13 x1024 3.987 BFLOPs 30 conv 425 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 425 0.147 BFLOPs 31 detection mask_scale: Using default '1.000000' Loading weights from yolo.weights...Done! data/person.jpg: Predicted in 4.606814 seconds. horse: 91% dog: 85% person: 85% |
cfg/yolov2.cfgについての詳細は理解していませんが、他のファイルでは推定に失敗してしまったのでこちらを指定しています。
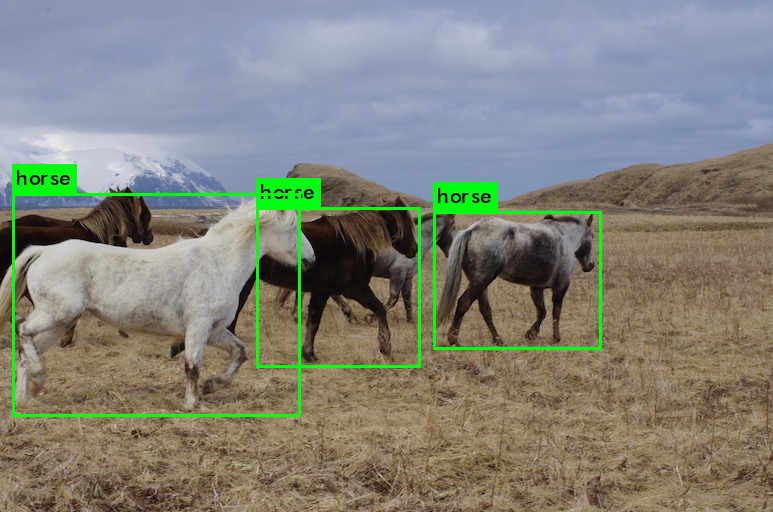
predictions.pngという画像ファイルが生成されており、物体検出が行われていることが分かります。
生成画像
|
1 2 3 |
from PIL import Image img = Image.open('predictions.png') img |

物体検出が行われ「犬」と「人間」と「馬」が表示されています。
元画像
|
1 2 3 |
from PIL import Image img = Image.open('data/person.jpg') img |

参考までに元の画像です。
その他にdataディレクトリ配下には、いくつかサンプルが用意されておりいろいろな物体検出を確認することが出来ます。